模式开发之旅(14):享元模式
2010-07-31 11:55:43享元模式的原理
所谓“享元”,顾名思义就是被共享的单元。享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。具体来讲,当一个系统中存在大量重复对象的时候,我们就可以利用享元模式,将对象设计成享元,在内存中只保留一份实例,供多处代码引用,这样可以减少内存中对象的数量,以起到节省内存的目的。实际上,不仅仅相同对象可以设计成享元,对于相似对象,我们也可以将这些对象中相同的部分(字段),提取出来设计成享元,让这些大量相似对象引用这些享元。
享元模式: 运用共享技术有效地支持大量细颗度的对象。
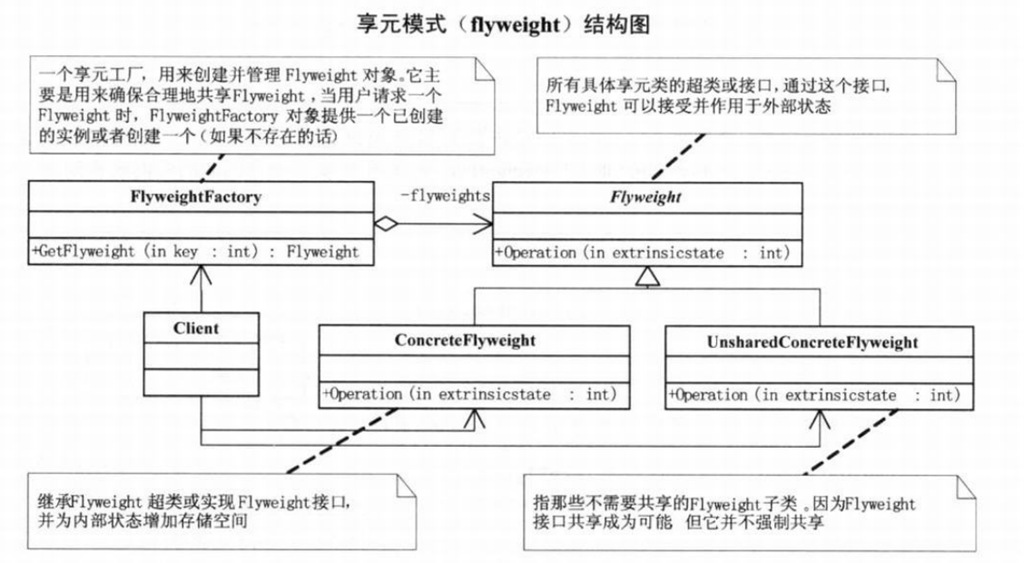
享元模式的实现
享元模式的代码实现非常简单,主要是通过工厂模式,在工厂类中,通过一个 Map 或者 List 来缓存已经创建好的享元对象,以达到复用的目的。
比如我们要实现一个文本编辑器,假设这个编辑器只支持26个大写英文字母的输入。编辑器可以编写成千上万的内容,如果这些内容都保存在内存中就会造成内存过多的分配。而当前整个文本编辑器是由26个大写字母的任意组成的,这时我们就可以用享元模式,最多分配26个字母的内存,编辑器共享分配的内存既可。
public class FlyweightFactory
{
private static Dictionary<WordType, BaseWord> _BaseWordDictionary = new Dictionary<WordType, BaseWord>();
private static object GetWord_Lock = new object();
public static BaseWord GetWord(WordType wordType)
{
BaseWord baseWord = null;
if (_BaseWordDictionary.ContainsKey(wordType))//双if+lock
{
baseWord = _BaseWordDictionary[wordType];
}
else
{
lock (GetWord_Lock)
{
if (_BaseWordDictionary.ContainsKey(wordType))
{
baseWord = _BaseWordDictionary[wordType];
}
else
{
switch (wordType)
{
case WordType.A:
baseWord = new A();
break;
case WordType.B:
baseWord = new B();
break;
case WordType.C:
baseWord = new C();
break;
//...其它字母
default:
throw new Exception("wrong wordType");
}
_BaseWordDictionary[wordType] = baseWord;
}
}
}
return baseWord;
}
}
享元模式 VS 单例、缓存、对象池
享元与单例
在单例模式中,一个类只能创建一个对象,而在享元模式中,一个类可以创建多个对象,每个对象被多处代码引用共享。实际上,享元模式有点类似于之前讲到的单例的变体:多例。
尽管从代码实现上来看,享元模式和多例有很多相似之处,但从设计意图上来看,它们是完全不同的。应用享元模式是为了对象复用,节省内存,而应用多例模式是为了限制对象的个数。
享元与缓存
在享元模式的实现中,我们通过工厂类来“缓存”已经创建好的对象。这里的“缓存”实际上是“存储”的意思,跟我们平时所说的“数据库缓存”“CPU 缓存”“MemCache 缓存”是两回事。我们平时所讲的缓存,主要是为了提高访问效率,而非复用。
享元与对象池
虽然对象池、连接池、线程池、享元模式都是为了复用,但是,如果我们再细致地抠一抠“复用”这个字眼的话,对象池、连接池、线程池等池化技术中的“复用”和享元模式中的“复用”实际上是不同的概念。
池化技术中的“复用”可以理解为“重复使用”,主要目的是节省时间(比如从数据库池中取一个连接,不需要重新创建)。在任意时刻,每一个对象、连接、线程,并不会被多处使用,而是被一个使用者独占,当使用完成之后,放回到池中,再由其他使用者重复利用。享元模式中的“复用”可以理解为“共享使用”,在整个生命周期中,都是被所有使用者共享的,主要目的是节省空间。

