Kafka知识点总结
2022-04-30 20:53:37Kafka最初是领英公司开发的消息流组件,后来捐献给了Apche。
一、拓扑结构
Broker 是 Kafka 集群中的核心服务器,你可以把它想象成一个邮局:
- 生产者(Producer)就像寄信人,把消息(信件)送到 Broker(邮局)
- 消费者(Consumer)就像收信人,从 Broker 取走自己的消息
- 一个 Kafka 集群通常由多个 Broker 组成,共同处理消息存储和转发Broker 的核心职责
1. 消息存储中心
- 持久化存储 :所有消息最终都会写入磁盘,而不仅仅是内存
- 分区管理 :每个 Broker 负责存储某些分区的数据
- 日志分段 :将大日志文件分割成多个段(segment),便于维护和清理
2. 消息路由中心
- 维护所有主题/分区的元数据信息
- 决定生产者应该把消息发送到哪个分区
- 协调消费者从哪个分区获取消息
3. 副本协调者
- 管理 Leader 副本和 Follower 副本的同步
- 监控副本的健康状态
- 在 Leader 失效时组织新的选举Broker的工作流程
Kafka的存储结构就像一本书的目录:
- 主题(Topic) :相当于书的标题,是消息的分类。比如"用户注册"、"订单支付"等。
- 分区(Partition) :相当于书的章节,每个主题可以被分成多个分区。分区使Kafka可以并行处理消息。
- 副本(Replica) :相当于书的复印本,每个分区可以有多个副本(通常3个)。分为Leader副本(主本)和Follower副本(副本)。
Kafka 会智能地将副本分布在不同 Broker 上:
- 同一个分区的不同副本不会放在同一个 Broker
- 尽量将分区的 Leader 均匀分布在所有 Broker 例如下图有 2个 Broker 和 1 个主题(分区数=3,副本数=2):
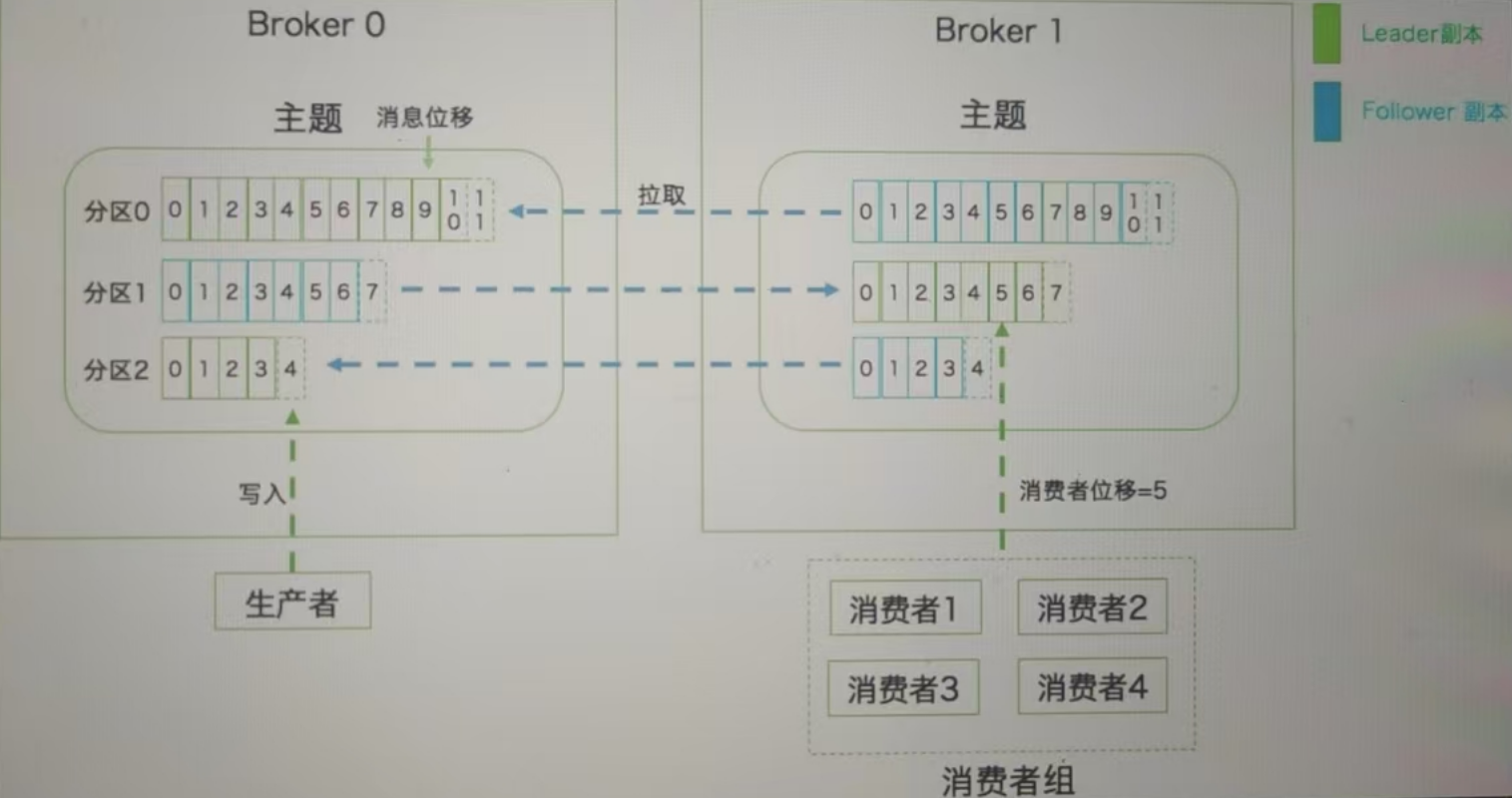 Kafka的消息存储就像写日记:
Kafka的消息存储就像写日记:
- 消息以追加(append-only) 方式写入分区,不可修改
- 每个消息都有一个位移(offset) ,相当于日记的行号
- 消息按时间保留(默认7天),超过时间自动删除
- 分区日志被分成多个段(segment) 文件,便于管理
- 基于日志结构构建的消息引擎:消费消息时是读取日志文件,消息不会删除
二、消息流程
1. 消息写入流程
- 生产者连接到任意 Broker 获取元数据
- Broker 返回主题分区信息和 Leader Broker 位置
- 生产者直接将消息发送给对应分区的 Leader Broker
- Leader 将消息写入本地日志
- Leader 等待 Follower 副本同步完成(根据 acks 配置)
- 返回确认响应给生产者
2. 消息读取流程
- 消费者连接到任意 Broker 获取元数据
- Broker 返回主题分区信息和 Leader Broker 位置
- 消费者直接从对应分区的 Leader Broker 拉取消息
- Broker 根据消费者提交的 offset 返回相应的消息批次
- 消费者处理完消息后提交新的 offset
3. 实操
- 开发环境部署
version: "2"
services:
kafka:
image: docker.io/bitnami/kafka:3.6
ports:
- "9092:9092"
environment:
# KRaft settings
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093
# Listeners
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.5:9092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- 异步方法实际是同步的
// 发布者
public static async Task Run()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.2.5:9092",
CompressionType = CompressionType.Gzip,
BatchSize = 1000000
};
using var producer = new ProducerBuilder<Null, string>(config).Build();
var stopSatuch = Stopwatch.StartNew();
try
{
const string topic = "sample";
for (var i = 0; i < 100; i++)
{
var messageValue = $"Hello World! Kafka!-{i}";
var result = await producer.ProduceAsync(topic, new Message<Null, string>
{
// Key = "key"
// Headers =
// Timestamp =
Value = messageValue
});
// Console.WriteLine($"消息已发送[{result.Value}]到[{result.TopicPartitionOffset}]");
}
}
catch (ProduceException<string, string> e)
{
Console.WriteLine($"发送失败: {e.Error.Reason}");
}
Console.WriteLine($"ProduceAsync 耗时:{stopSatuch.Elapsed}");
}
// 消费者
public static void Run()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.2.5:9092",
GroupId = "consumer.group.hello",
AutoCommitIntervalMs = 100,
EnableAutoCommit = false,
// 拉取的最小数据量
FetchMinBytes = 10,
FetchMaxBytes = 1,
FetchWaitMaxMs = 500,
MaxPartitionFetchBytes = 1,
};
using var consumer = new ConsumerBuilder<Ignore, string>(config).Build();
consumer.Subscribe("sample");
consumer.Unsubscribe();
Console.WriteLine("等待消息……");
while (true) //消费方法是一个阻塞式方法,所以不会一直循环
{
var consumeResult = consumer.Consume();
consumer.Commit();
consumer.Committed(TimeSpan.Zero);
Console.WriteLine($"收到消息:[{consumeResult.Message.Value}] 来自 [{consumeResult.TopicPartitionOffset}]");
}
}
- 同步方法实际是异步的
// 发布者
public static void Run()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.2.5:9092"
};
using var producer = new ProducerBuilder<Null, string>(config).Build();
var stopSatuch = Stopwatch.StartNew();
try
{
const string topic = "sample";
for (var i = 0; i < 100; i++)
{
producer.Produce(topic, new Message<Null, string>
{
Value = $"Hello World! Kafka!-{i}",
},
report =>
{
// Console.WriteLine($"已发送:[{report.Value}],Offset:{report.TopicPartitionOffset}");
});
}
}
catch (ProduceException<string, string> e)
{
Console.WriteLine($"发送失败: {e.Error.Reason}");
}
producer.Flush(CancellationToken.None);
Console.WriteLine($"Produce 耗时:{stopSatuch.Elapsed}");
}
// 消费者
public static void Run()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.2.5:9092",
GroupId = "consumer.group.hello",
AutoOffsetReset = AutoOffsetReset.Earliest,
};
using var consumer = new ConsumerBuilder<Ignore, string>(config).Build();
consumer.Subscribe("sample");
Console.WriteLine("等待消息……");
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine($"收到消息:[{consumeResult.Message.Value}] 来自 [{consumeResult.TopicPartitionOffset}]");
}
}
4. 消费者关键参数
- GroupId
- AutoCommitIntervalMs
- EnableAutoCommit
- FetchMinBytes
- FetchMaxBytes
- FetchWaitMasMs
- MaxPartitionFetchBytes
5. 消息压缩和解压
三、消费者位移
想象你正在读一本很厚的书,为了记住你读到哪里了,你会使用一个书签。Kafka的"消费者位移"就类似于这个书签,它记录了消费者在Kafka主题(topic)中读取消息的位置。
1. 为什么需要消费者位移?
- 记住读取位置:当消费者重启时,知道从哪里继续读
- 避免重复消费:不会重复读取已经处理过的消息
- 支持多消费者:不同消费者可以跟踪各自的读取进度
2. 位移是如何工作的?
Kafka将消息存储在分区(partition)中,每个分区中的消息都有一个从0开始递增的偏移量(offset)。消费者位移就是记录消费者在这个分区中已经读取到了哪个偏移量。
举个例子:
- 分区中有消息:偏移量0、1、2、3、4、5...
- 如果你已经处理到偏移量3,那么你的消费者位移就是3
- 下次就会从偏移量4开始读取
Kafka使用一个特殊的主题__consumer_offsets来存储所有消费者的位移信息。这样即使消费者重启,也能找到上次的读取位置。
3. 位移提交
消费者处理完消息后,需要"提交"位移,告诉Kafka:"我已经处理到这里了!"。这就像你在读书时定期移动书签的位置。
有两种主要提交方式:
- 自动提交:Kafka每隔一段时间自动帮你提交,默认5秒,是一种延迟提交机制,会有重复消费风险
- 手动提交:自己决定何时提交(更精确但更复杂)
public static void Run()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.2.5:9092",
GroupId = "consumer.group.hello",
AutoOffsetReset = AutoOffsetReset.Earliest,
// 关闭自动提交位移
EnableAutoCommit = false,
};
using var consumer = new ConsumerBuilder<Ignore, string>(config).Build();
consumer.Subscribe("sample");
Console.WriteLine("等待消息……");
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine($"收到消息:[{consumeResult.Message.Value}] 来自 [{consumeResult.TopicPartitionOffset}]");
// 处理完成后手动提交位移
consumer.Commit(consumeResult);
}
}
4. 重设位移
- 位移维度
- 时间维度
public static void Run()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.2.5:9092",
GroupId = "consumer.group.hello",
AutoOffsetReset = AutoOffsetReset.Earliest,
PartitionAssignmentStrategy = PartitionAssignmentStrategy.CooperativeSticky
};
using var consumer = new ConsumerBuilder<Ignore, string>(config).Build();
var topicPartition = new TopicPartition("sample", new Partition(0));
var tpOffset = new TopicPartitionOffset(topicPartition, new Offset(0));
consumer.Assign(tpOffset);
var timestamp = new Timestamp(DateTime.Now.AddMinutes(-30));
var dateTimeOffset = new TopicPartitionTimestamp(new TopicPartition("sample", new Partition(0)), timestamp);
//
// var timestamp = new Timestamp(new DateTime(2023, 11, 1));
// var dateTimeOffset = new TopicPartitionTimestamp(new TopicPartition("sample", new Partition(0)), timestamp);
// var tpos = consumer.OffsetsForTimes(new[] { dateTimeOffset }, TimeSpan.FromSeconds(5));
// consumer.Assign(tpos);
consumer.Subscribe("sample");
Console.WriteLine("等待消息……");
while (true)
{
var consumeResult = consumer.Consume();
// var offsets = consumer.Committed(TimeSpan.FromSeconds(5));
//
// consumer.Seek(new TopicPartitionOffset(consumeResult.TopicPartition, new Offset(offsets[0].Offset - 2)));
//
// consumer.Seek(new TopicPartitionOffset(consumeResult.TopicPartition, new Offset(offsets[0].Offset)));
//
// consumer.Seek(new TopicPartitionOffset(consumeResult.TopicPartition,Offset.Beginning));
Console.WriteLine($"收到消息:[{consumeResult.Message.Value}] 来自 [{consumeResult.TopicPartitionOffset}]");
}
}
5. 位移管理的重要性
如果管理不当,可能会出现:
- 重复消费:位移提交晚了,重启后重新读取已处理的消息
- 消息丢失:位移提交早了,但消息还没处理完就崩溃了
四、副本备份机制
1. 副本的两种角色:
- Leader副本(主副本):
- 负责处理所有读写请求
- 每个分区只有一个Leader
- 生产者只向Leader写入数据
- Follower副本(从副本):
- 被动从Leader复制数据
- 不直接服务客户端请求
- 随时准备接替Leader的角色
2. 副本如何同步数据?
Kafka使用"ISR"(In-Sync Replicas,同步副本)机制来管理副本同步:
- Leader接收消息后,先写入本地日志
- Follower定期从Leader拉取新消息(pull模式)
- 成功复制的副本保持在ISR列表中
- 落后太多的副本会被移出ISR
3. 什么是"同步"副本?
一个副本被认为是"同步"的,必须满足:
- 与Leader保持网络连接
- 最近一段时间内(由
replica.lag.time.max.ms控制)从Leader获取了最新消息 - 消息不能落后太多(由
replica.lag.max.messages控制,新版已弃用)
4. 副本选举机制
当Leader失效时,Kafka会从ISR中选出一个新的Leader:
- 控制器(Controller)检测到Leader失效
- 从ISR列表中选择一个Follower晋升为Leader
- 如果ISR为空,可以配置是否允许从非同步副本中选举(
unclean.leader.election.enable)
5. 副本常见配置参数
replication.factor:副本数量(通常3)min.insync.replicas:最小同步副本数(决定写入成功条件)replica.lag.time.max.ms:副本最大延迟时间(默认10秒)
6. 数据一致性保证
完全可靠:
acks=all // 要求所有ISR副本都确认 min.insync.replicas=2 // 至少2个副本确认中等可靠:
acks=1 // 只需Leader确认不保证可靠
acks=0 // 不需要确认
可能丢失数据,但吞吐量最高
五、高性能机制
- 批量消息发送:底层批量发送
- 顺序磁盘I/O:顺序读写>随机读写
- 页缓存(Page Cache)优化:内核空间缓存
- 零拷贝技术(Zero-Copy):操作系统底层技术
- 消息压缩
- 吞吐量:LZ4>Snappy>zstd=gzip
- 压缩比:zstd>gzip>lz4>snappy
- 分区并行处理
六、消费者组和重平衡
消费者组和重平衡是Kafka实现弹性扩展和高可用的关键机制:
- 消费者组:让多个消费者协同工作,分摊负载。
- 重平衡:当消费者组的成员发生变化时(如新增、离开或崩溃),Kafka会重新分配分区给剩余的消费者,这个过程就叫"重平衡"。自动适应变化,但需要合理配置以减少性能影响
想象一个团队一起完成一项任务:消费者组就是一群共同工作的消费者,它们一起消费同一个主题的消息,但组内每个消费者只负责处理一部分消息。
1. 关键特点:
分工合作:组内消费者平均分配主题的所有分区
消息只被消费一次:同一条消息只会被组内的一个消费者处理
横向扩展:通过增加消费者可以提高处理能力
2. 消费者组的工作原理
举个例子:
- 有一个主题包含3个分区(P0,P1,P2)
- 消费者组内有3个消费者(C1,C2,C3)
分配结果:
- C1 ← P0
- C2 ← P1
- C3 ← P2
如果组内有4个消费者呢?
- 会有一个消费者空闲,因为只有3个分区需要分配
3. 触发重平衡的情况:
- 新消费者加入组
- 消费者离开组(主动退出或崩溃)
- 订阅的主题分区数发生变化
- 消费者会话超时(心跳停止)
4. 重平衡的过程
- 所有消费者暂停消费
- 选举组协调者:选出一个负责协调的消费者
- 重新分配分区:按照分配策略(如Range、RoundRobin等)计算新分配方案
- 同步新分配方案:告诉每个消费者它们负责哪些分区
- 恢复消费:消费者从新的分配位置开始消费
5. 重平衡的影响
优点:
- 自动适应消费者数量变化
- 保证负载均衡
缺点:
- 期间整个消费者组停止工作(短暂不可用)
- 频繁重平衡会降低系统性能
6. 如何减少重平衡?
- 合理设置会话超时:
session.timeout.ms参数 - 优化心跳间隔:
heartbeat.interval.ms参数 - 避免频繁启停消费者
- 使用静态成员资格(Kafka 2.3+特性)
消费者实例的数量==该组所订阅主题的全部分分区总数
七、分区分配策略
想象你有一堆任务(分区)和一群工人(消费者),需要决定哪个工人做哪些任务。Kafka的分区分配策略就是用来决定"哪个消费者消费哪个分区"的规则。
1. 为什么需要分配策略?
- 负载均衡:让每个消费者处理大致相同数量的分区
- 提高效率:减少不必要的网络传输
- 容错处理:消费者加入或离开时能合理重新分配
2. 三种主要分配策略
Range(范围分配)
工作原理:
按分区编号顺序划分范围
每个消费者分配连续的一段分区
示例:
有3个消费者(C1,C2,C3)和7个分区(P0-P6)
分配结果:
- C1: P0,P1,P2
- C2: P3,P4
- C3: P5,P6
特点:
- 实现简单
- 可能导致分配不均(如上例中C1比其他人多一个分区)
- 是Kafka默认的分配策略
RoundRobin(轮询分配)
工作原理:
像发牌一样轮流给每个消费者分配分区
考虑整个消费者组的所有主题
示例:
消费者组订阅了主题A(3分区)和主题B(3分区)
有3个消费者(C1,C2,C3)
分配结果:
- C1: A-P0, B-P0
- C2: A-P1, B-P1
- C3: A-P2, B-P2
特点:
- 分配最均衡
- 需要消费者组内所有消费者订阅相同的主题列表
- 在消费者订阅不同主题时可能表现不佳
- Sticky(粘性分配)
工作原理:
尽量保持原有分配不变
只在必要时做最小化的调整
示例: 初始状态:
- C1: P0,P3
- C2: P1,P4
- C3: P2,P5
当C3离开时:
- 不是完全重新分配
- 而是将C3的分区分配给C1和C2:
- C1: P0,P3,P2
- C2: P1,P4,P5
特点:
- 减少重平衡时的分区移动
- 降低开销(避免大量状态转移)
- 是Kafka 0.11版本引入的优化策略
3. 分配策略如何选择?
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Range | 实现简单 | 可能分配不均 | 主题少且分区数可被消费者整除 |
| RoundRobin | 分配最均衡 | 要求订阅相同主题 | 消费者订阅相同主题列表 |
| Sticky | 重平衡开销小 | 首次分配可能不均 | 频繁重平衡的环境 |
八、集群架构模式
1.传统的Zookeeper集群模式
version: "3"
services:
zookeeper:
image: docker.io/bitnami/zookeeper:3.9
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka1:
image: docker.io/bitnami/kafka:3.6
container_name: kafka1
ports:
- "19092:9092"
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.251:19092
restart: always
depends_on:
- zookeeper
kafka2:
image: docker.io/bitnami/kafka:3.6
container_name: kafka2
ports:
- "29092:9092"
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.251:29092
restart: always
depends_on:
- zookeeper
kafka3:
image: docker.io/bitnami/kafka:3.6
container_name: kafka3
ports:
- "39092:9092"
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.251:39092
restart: always
depends_on:
- zookeeper
kafka-ui:
image: provectuslabs/kafka-ui:master
container_name: kafka-ui
ports:
- "8080:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local # kafka 集群名称
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka1:9092 # kafka集群地址
- DYNAMIC_CONFIG_ENABLED= 'true' # 启动动态配置 kafka
- AUTH_TYPE=LOGIN_FORM # 启用登录授权
- SPRING_SECURITY_USER_NAME=admin # 账号
- SPRING_SECURITY_USER_PASSWORD=admin # 密码
depends_on:
- kafka1
- kafka2
- kafka3
2.全新的Kraft(Kafka Raft)集群模式(3.0版本)
services:
kafka1:
image: docker.io/bitnami/kafka
container_name: kafka1
ports:
- "19092:9092"
environment:
# KRaft settings
- KAFKA_KRAFT_CLUSTER_ID=MTIzNDU2Nzg5MGFiY2RlZg # 纯英文和数字组成的字符串+Base64进行编码
- KAFKA_CFG_NODE_ID=1
- KAFKA_CFG_PROCESS_ROLES=broker,controller # 节点角色
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# Listeners
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 # 定义kafka服务端socket监听端口(Docker内部的ip地址和端口)
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # 定义安全协议
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.251:19092 # 定义外网访问地址(宿主机ip地址和端口),填写宿主机IP地址
restart: always
kafka2:
image: docker.io/bitnami/kafka
container_name: kafka2
ports:
- "29092:9092"
environment:
- KAFKA_CFG_NODE_ID=2
# KRaft settings
- KAFKA_KRAFT_CLUSTER_ID=MTIzNDU2Nzg5MGFiY2RlZg
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# Listeners
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.251:29092
restart: always
kafka3:
image: docker.io/bitnami/kafka:3.6
container_name: kafka3
ports:
- "39092:9092"
environment:
- KAFKA_CFG_NODE_ID=3
# KRaft settings
- KAFKA_KRAFT_CLUSTER_ID=MTIzNDU2Nzg5MGFiY2RlZg
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
# Listeners
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.251:39092
restart: always
kafka-ui:
image: provectuslabs/kafka-ui:master
container_name: kafka-ui
ports:
- "8080:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local # kafka 集群名称
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka1:9092 # kafka集群地址
- DYNAMIC_CONFIG_ENABLED= 'true' # 启动动态配置 kafka
- AUTH_TYPE=LOGIN_FORM # 启用登录授权
- SPRING_SECURITY_USER_NAME=admin # 账号
- SPRING_SECURITY_USER_PASSWORD=admin # 密码
depends_on:
- kafka1
- kafka2
- kafka3
九、Kafka 与 RabbitMQ 关键能力差异
| 维度 | Kafka | RabbitMQ |
|---|---|---|
| 设计目标 | 高吞吐、持久化、流处理 | 灵活路由、可靠投递 |
| 架构模型 | 分布式日志系统 | 消息代理(Broker) |
| 数据存储 | 磁盘持久化(顺序IO) | 内存为主(可配置持久化) |
| 协议支持 | 自有协议 | 支持 AMQP、STOMP、MQTT 等 |
1. 消息消费方式
- Kafka:
- 基于位移(offset)的拉取(pull)模式
- 消费者控制读取节奏
- 消息可重复消费(通过重置offset)
- RabbitMQ:
- 推送(push)模式为主
- Broker 控制推送速率
- 消息确认后自动删除(除非持久队列)
2. 消息路由
- Kafka:
- 简单分区路由(可自定义分区器)
- 无复杂路由规则
- RabbitMQ:
- 支持多种交换器类型(direct/topic/fanout/headers)
- 灵活的路由规则
3. 顺序保证
- Kafka:
- 分区内严格有序
- 全局无序(除非单分区)
- RabbitMQ:
- 单个队列有序
- 多消费者时顺序无法保证
4. 吞吐量对比
| 指标 | Kafka | RabbitMQ |
|---|---|---|
| 单机吞吐量 | 100K+/秒 | 10K-50K/秒 |
| 延迟 | 毫秒级 | 微秒级 |
| 适用场景 | 大数据量场景 | 低延迟场景 |
5. 消息回溯
- Kafka:
- 天然支持(通过offset重置)
- 可重复处理历史数据
- RabbitMQ:
- 需特殊设计(如死信队列)
- 通常消费后即删除
典型应用场景对比
适合 Kafka 的场景
- 日志收集与分析(ELK 体系)
- 流式数据处理(用户行为追踪)
- 事件溯源(Event Sourcing)
- 大数据管道(Hadoop/Spark 数据源)
- 消息回溯(如对账补单)
适合 RabbitMQ 的场景
- 业务解耦(订单→库存→支付)
- 即时通讯(聊天消息)
- 任务队列(异步处理)
- 金融交易(需要强一致性)
- 复杂路由(如根据消息头路由)

