模式开发之旅(27):访问者模式
2010-10-02 16:41:48访问者模式:表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
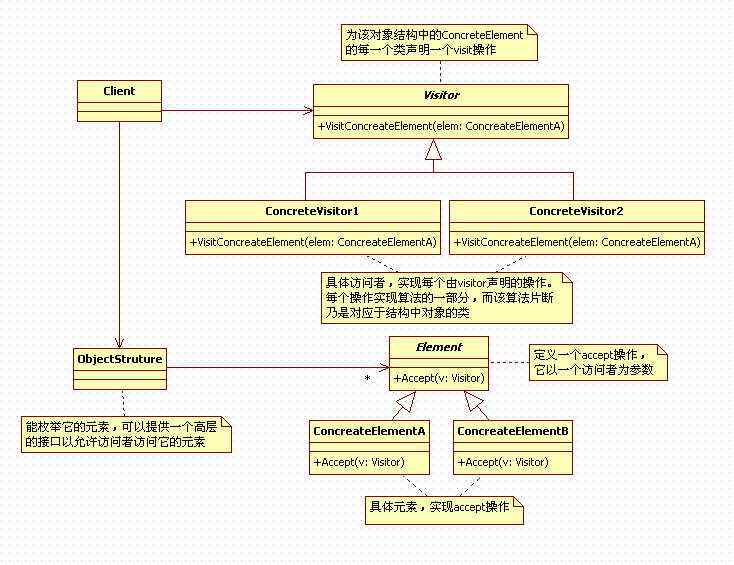
大部分设计模式的原理和实现都很简单,不过也有例外,比如今天要讲的访问者模式。它可以算是 23 种经典设计模式中最难理解的几个之一。因为它难理解、难实现,应用它会导致代码的可读性、可维护性变差,所以,访问者模式在实际的软件开发中很少被用到,在没有特别必要的情况下,建议不要使用访问者模式。
访问者模式诞生的思维过程
假设我们从网站上爬取了很多资源文件,它们的格式有三种:PDF、PPT、Word。我们现在要开发一个工具来处理这批资源文件。这个工具的其中一个功能是,把这些资源文件中的文本内容抽取出来放到 txt 文件中。
实现这个功能并不难,不同的人有不同的写法,我将其中一种代码实现方式贴在这里。其中,ResourceFile 是一个抽象类,包含一个抽象方法 Extract2txt()。PdfFile、PPTFile、WordFile 都继承 ResourceFile 类,并且重写了 Extract2txt() 方法。在 ToolApplication 中,我们可以利用多态特性,根据对象的实际类型,来决定执行哪个方法。
public abstract class ResourceFile
{
protected string filePath;
public ResourceFile(string filePath)
{
this.filePath = filePath;
}
public abstract void Extract2txt();
}
public class PPTFile : ResourceFile
{
public PPTFile(string filePath):base(filePath)
{
}
public override void Extract2txt() {
//...省略一大坨从PPT中抽取文本的代码...
//...将抽取出来的文本保存在跟filePath同名的.txt文件中...
Console.WriteLine("Extract PPT.");
}
}
public class PdfFile : ResourceFile {
public PdfFile(string filePath) : base(filePath)
{
}
public override void Extract2txt()
{
//... System.out.println("Extract PDF.");
}
}
public class WordFile : ResourceFile
{
public WordFile(string filePath) : base(filePath)
{
}
public override void Extract2txt()
{
//... System.out.println("Extract Word.");
}
}
// 运行结果是:
// Extract PDF.
// Extract WORD.
// Extract PPT.
public class ToolApplication
{
public static void main(string[] args)
{
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
foreach (var resourceFile in resourceFiles)
{
resourceFile.Extract2txt();
}
}
private static List<ResourceFile> listAllResourceFiles(string resourceDirectory)
{
List<ResourceFile> resourceFiles = new List<ResourceFile>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.Add(new PdfFile("a.pdf"));
resourceFiles.Add(new WordFile("b.word"));
resourceFiles.Add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
如果工具的功能不停地扩展,不仅要能抽取文本内容,还要支持压缩、提取文件元信息(文件名、大小、更新时间等等)构建索引等一系列的功能,那如果我们继续按照上面的实现思路,就会存在这样几个问题:
- 违背开闭原则,添加一个新的功能,所有类的代码都要修改;
- 虽然功能增多,每个类的代码都不断膨胀,可读性和可维护性都变差了;
- 把所有比较上层的业务逻辑都耦合到 PdfFile、PPTFile、WordFile 类中,导致这些类的职责不够单一,变成了大杂烩。
针对上面的问题,我们常用的解决方法就是拆分解耦,把业务操作跟具体的数据结构解耦,设计成独立的类。这里我们按照访问者模式的演进思路来对上面的代码进行重构。重构之后的代码如下所示。
public abstract class ResourceFile
{
protected string filePath;
public ResourceFile(string filePath)
{
this.filePath = filePath;
}
}
public class PPTFile : ResourceFile
{
public PPTFile(string filePath):base(filePath)
{
}
}
//PdfFile,WordFile代码省略
public class Extractor
{
public void Extract2txt(PPTFile pptFile)
{
//...
Console.WriteLine("Extract PPT.");
}
public void Extract2txt(PdfFile pdfFile)
{
//...
Console.WriteLine("Extract PDF.");
}
public void Extract2txt(WordFile wordFile)
{
//...
Console.WriteLine("Extract Word.");
}
}
public class ToolApplication
{
public static void main(string[] args)
{
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
foreach (var resourceFile in resourceFiles)
{
extractor.Extract2txt(resourceFile); //这一行会报错
}
}
private static List<ResourceFile> listAllResourceFiles(string resourceDirectory)
{
List<ResourceFile> resourceFiles = new List<ResourceFile>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.Add(new PdfFile("a.pdf"));
resourceFiles.Add(new WordFile("b.word"));
resourceFiles.Add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
这其中最关键的一点设计是,我们把抽取文本内容的操作,设计成了三个重载方法。不过,如果你足够细心,就会发现,上面的代码是编译通过不了的,有一行会报错,我们再来看一下代码,看看是怎么解决这个问题的。
public abstract class ResourceFile
{
protected string filePath;
public ResourceFile(string filePath)
{
this.filePath = filePath;
}
public abstract void Accept(Extractor extractor);
}
public class PPTFile : ResourceFile
{
public PPTFile(string filePath):base(filePath)
{
}
public override void Accept(Extractor extractor)
{
extractor.Extract2txt(this);
}
}
//PdfFile,WordFile代码省略
//Extractor代码不变
public class ToolApplication
{
public static void main(string[] args)
{
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
foreach (var resourceFile in resourceFiles)
{
resourceFile.Accept(extractor); //根据多态特性,程序会调用实际类型的Accept方法
}
}
private static List<ResourceFile> listAllResourceFiles(string resourceDirectory)
{
List<ResourceFile> resourceFiles = new List<ResourceFile>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.Add(new PdfFile("a.pdf"));
resourceFiles.Add(new WordFile("b.word"));
resourceFiles.Add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
这个实现思路是不是很有技巧?这是理解访问者模式的关键所在,这也是访问者模式不好理解的原因。
现在,如果要继续添加新的功能,比如前面提到的压缩功能,根据不同的文件类型,使用不同的压缩算法来压缩资源文件,那我们该如何实现呢?我们需要实现一个类似 Extractor 类的新类 Compressor 类,在其中定义三个重载,实现对不同类型资源文件的压缩。除此之外,我们还要在每个资源文件类中定义新的 Accept 重载方法。
public abstract class ResourceFile
{
protected string filePath;
public ResourceFile(string filePath)
{
this.filePath = filePath;
}
public abstract void Accept(Extractor extractor);
public abstract void Accept(Compressor compressor);
}
public class PPTFile : ResourceFile
{
public PPTFile(string filePath):base(filePath)
{
}
public override void Accept(Extractor extractor)
{
extractor.Extract2txt(this);
}
public override void Accept(Compressor compressor)
{
compressor.Compress(this);
}
}
//PdfFile,WordFile代码省略
//Extractor代码不变
public class ToolApplication
{
public static void main(string[] args)
{
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
foreach (var resourceFile in resourceFiles)
{
resourceFile.Accept(extractor);
}
Compressor compressor = new Compressor();
foreach (var resourceFile in resourceFiles)
{
resourceFile.Accept(compressor);
}
}
private static List<ResourceFile> listAllResourceFiles(string resourceDirectory)
{
List<ResourceFile> resourceFiles = new List<ResourceFile>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.Add(new PdfFile("a.pdf"));
resourceFiles.Add(new WordFile("b.word"));
resourceFiles.Add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
上面代码还存在一些问题,添加一个新的业务,还是需要修改每个资源文件类,违反了开闭原则。针对这个问题,我们抽象出来一个 Visitor 接口,包含是三个命名非常通用的 Visit() 重载方法,分别处理三种不同类型的资源文件。具体做什么业务处理,由实现这个 Visitor 接口的具体的类来决定,比如 Extractor 负责抽取文本内容,Compressor 负责压缩。当我们新添加一个业务功能的时候,资源文件类不需要做任何修改,只需要修改 ToolApplication 的代码就可以了。
按照这个思路我们可以对代码进行重构,重构之后的代码如下所示:
public abstract class ResourceFile
{
protected string filePath;
public ResourceFile(string filePath)
{
this.filePath = filePath;
}
public abstract void Accept(Visitor visitor);
}
public class PPTFile : ResourceFile
{
public PPTFile(string filePath):base(filePath)
{
}
public override void Accept(Visitor visitor)
{
visitor.Visit(this);
}
}
//PdfFile,WordFile代码省略
public interface Visitor
{
void Visit(PPTFile pdfFile);
void Visit(PdfFile pdfFile);
void Visit(WordFile pdfFile);
}
public class Extractor : Visitor
{
public void Visit(PPTFile pptFile)
{
//...
Console.WriteLine("Extract PPT.");
}
public void Visit(PdfFile pdfFile)
{
//...
Console.WriteLine("Extract PDF.");
}
public void Visit(WordFile wordFile)
{
//...
Console.WriteLine("Extract Word.");
}
}
public class Compressor : Visitor
{
public void Visit(PPTFile pptFile)
{
//...
Console.WriteLine("Compress PPT.");
}
public void Visit(PdfFile pdfFile)
{
//...
Console.WriteLine("Extract PDF.");
}
public void Visit(WordFile wordFile)
{
//...
Console.WriteLine("Extract Word.");
}
}
public class ToolApplication
{
public static void main(string[] args)
{
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
foreach (var resourceFile in resourceFiles)
{
resourceFile.Accept(extractor);
}
Compressor compressor = new Compressor();
foreach (var resourceFile in resourceFiles)
{
resourceFile.Accept(compressor);
}
}
private static List<ResourceFile> listAllResourceFiles(string resourceDirectory)
{
List<ResourceFile> resourceFiles = new List<ResourceFile>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.Add(new PdfFile("a.pdf"));
resourceFiles.Add(new WordFile("b.word"));
resourceFiles.Add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
一般来说,访问者模式针对的是一组类型不同的对象(PdfFile、PPTFile、WordFile)。不过,尽管这组对象的类型是不同的,但是,它们继承相同的父类(ResourceFile)或者实现相同的接口。在不同的应用场景下,我们需要对这组对象进行一系列不相关的业务操作(抽取文本、压缩等),但为了避免不断添加功能导致类(PdfFile、PPTFile、WordFile)不断膨胀,职责越来越不单一,以及避免频繁地添加功能导致的频繁代码修改,我们使用访问者模式,将对象与操作解耦,将这些业务操作抽离出来,定义在独立细分的访问者类(Extractor、Compressor)中。

