Redis知识点总结
2022-03-24 13:16:49一、知识点汇总
- 基础篇
- 功能特点介绍
- 系统架构
- 线程模型
- 单线程模式
- 多IO线程模式
- 入门篇
- 服务端与客户端
- 数据类型介绍和基础用法
- 在.net中使用Redis
- 持久化篇
- AOF日志
- AOF配置与日志文件
- 回写策略
- 重写机制
- RDB快照
- RDB配置
- 快走频率选择
- 混合持久化
- AOF日志
- 高可靠篇
- 主从集群模式
- 设置主从同步
- 主从同步的三个阶段
- 主从级联模式
- 主从集群故障问题
- 哨兵模式
- 哨兵机制基本流程
- 主观下线与客观下线
- 选主策略
- 主从集群模式
- 缓存篇
- 基础概念
- 缓存命中
- 缓存缺失
- 旁路缓存
- 缓存淘汰策略
- 随机策略
- TTL过期策略
- LRU算法策略
- LFU算法策略
- 缓存异常
- 缓存不一致
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 缓存污染
- 基础概念
二、基础篇
Redie特点
- 高性能:极低的延迟和极高的吞吐量
- 数据结构多样性:value支持丰富的数据结构
- 持久化:数据可以保存在硬盘
- 高可用性:主从复制、哨兵机制
- 发布订阅:
- 可扩展性:数据分片
系统架构
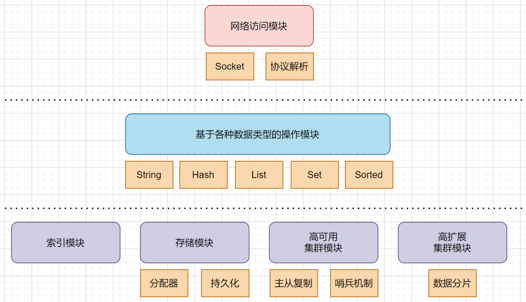
线程模型
Redis采用单线程模型,每秒10万级别处理能力
避免多线程的并非控制问题,主要是共享资源的访问,互斥锁(粗颗粒)
多路复用机制(网络IO)
IO多路复制机制:一个线程处理多个IO流
允许系统内核同时存在多个套接字(监听、已连接)
系统内核:事件回调机制
医院:病人(请求)---->分诊台(内核监听)---->转交给医生 一个医生(单线程)
Redis 6.0线程模型---->加入了多IO线程模式---->主要用于网络请求(网络IO,底层太快、单线程跟不上)
多线程默认关闭
config set io-threads-do-reads yes config set io-threads 4 (cup核心数-2)
三、入门篇
基础数据类型(5种)
- String字符串:任何形式的字节数据、二进制数据、单个数据最大512M
- Hash哈希:字典、Map、专门用来存储对象:字段/值 对
- List列表:有序的字符串元素集合(双向链表结构)、头部尾部高效插入、删除和访问、实现队列(先进先出)、栈(先进后出)
- Set集合:无序且元素唯一的字符串集合
- Sorted Set有序集合:元素唯一的字符串集合、每个元素关联一个分数(Score)、根据分数排序
特殊数据结构
- BItmap(位置):对string的扩展、对比特位进行独立的读写、海量的二值状态
- HyperLogLog:基数统计
- GEO:地理空间
- Stream:流
redis键的存储结构
Hash(Key)》哈希值》哈希桶下标
哈希表冲突的问题:两个不同的Key,得到相同的哈希值
- 链式哈希==》同一个哈希桶的多个元素用一个链表保存==》哈希冲突链
哈希重做==》rehash==》两个哈希表
- 给哈希表2分配更大的空间===》哈希表1的两倍
- 把哈希表1的所有数据==〉重新计算哈希值===》拷贝到哈希表2
- 迁移完毕==〉释放哈希表1===》哈希表2设置为主哈希表
问题:第2步存在大量的拷贝
渐进式哈希重做:哈希桶里面值一个个渐进式的拷贝
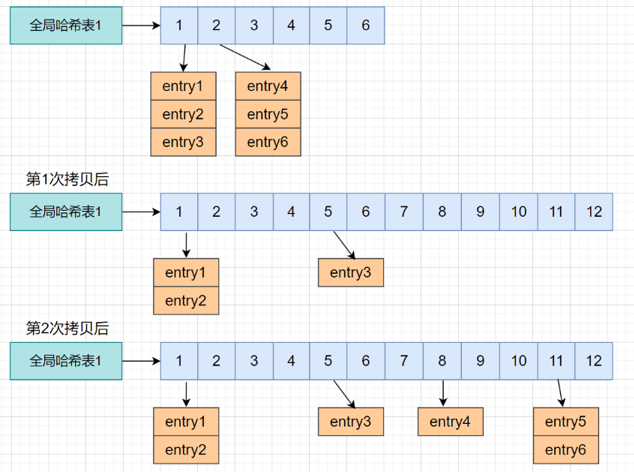
- 迁移过程中怎么读数据呢:先读哈希表1,没有时读哈希表2
- 哈希表1(主)》不会写〉只会往外搬 哈希表2(再读,搬完之后变成主)
redis值的数据类型
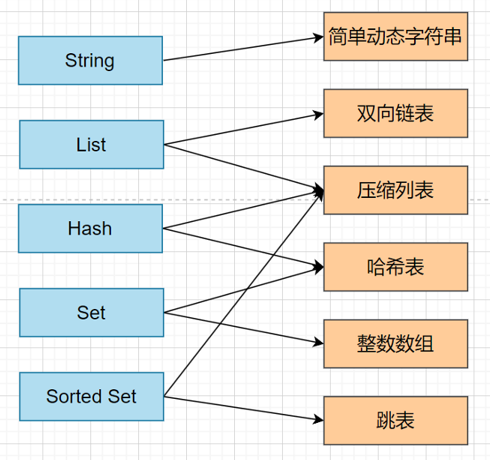
集合类型有5种
- Hash,上面已经介绍了
- 链表和双向链表,时间复杂度的On,这个不介绍了跟大学学的一样
- 压缩列表

- 跳表,链表上增加了多级索引
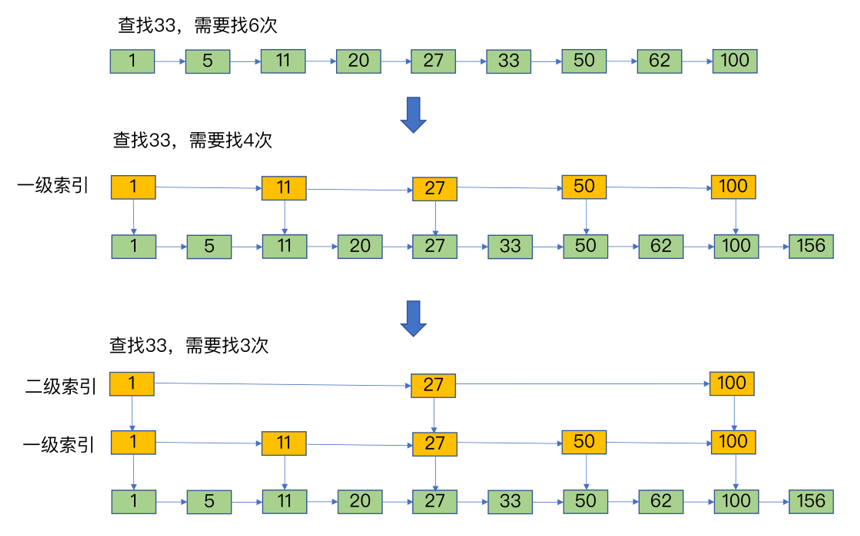
数据结构时间复杂度
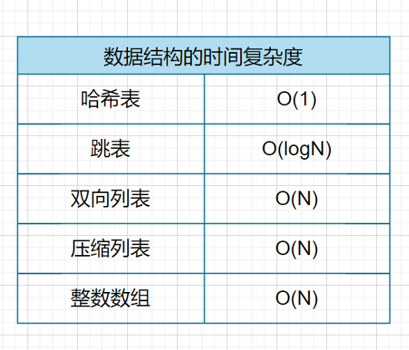
redis操作复杂度总结
- 单元素操作(HGET\HSET\HDEL\SADD\SREM\SRANDMEMBER)==》由底层数据结构决定
- 多元素操作(HMGET\HMSET)==》OM
- 范围操作==》遍历操作(HGETALL\SMEMERS\LRANG\ZRANGE)==》ON
- SCAN系列操作=》解决大范围操作阻塞
- 统计操作 (LLEN\SCARD)==》O1
- 例外M情况(LPOP(RPOP\LPUSH(RPUSH)==》O1
string===〉简单动态字符串(SDS)
使用常见:
- session:利用redis做session共享内存
- 自增和自减法:做一些网站的请求数量,或者论坛的点赞数,评论数
string底层:在功能中,除了上述这几个需求,尽量不要使用string类型,底层会浪费大量的内存空间。
- 如果使用raw编码,则每次开辟空间都会留一些空间,如果数据长度变了,则内存也会继续变大
- 如果使用embstr :它每次最多开辟64个字节的空间,只有44个字节时存储我们数据
- 如果操作redis的时候,内容长度小于等于44,则会自动选择embstr编码开辟空间
- 如果操作redis的时候,内容长度大于44的,使用ram编码,浪费空间
- 还有一个int:只是针对于写的数据是数值,才行。。切记只有整型才是int类型
底层就是因为开辟的组件的原因。。。所以会浪费空间,尽量不要使用string。
四、持久化篇
1. AOF日志
AOF配置与日志文件
- AOF:Append Only File—>写后日志 传统数据库(mysql)写前日志
- 默认没有开启:redies.conf
appendonly yes appendfilename “appendonly.aof”- 优点:写后日志不会阻塞之前的操作
- 风险: 如果刚执行完,来不及写日志就当机了,日志可能会丢失 AOF是主线程执行,虽然不会阻塞前面的操作,但是如果有大量命令同时执行时,可能阻塞后续操作
回写策略
- 同步写回 always
- 每秒写回 everysec
- 系统控制写回 no
重写机制
原因:AOF会越来也大===》带来新的性能问题
- 文件系统对单个文件大小限制
- 文件体积过大,会让后续追加写操作效率变低
- 恢复效率很低
重写过程==》后台线程
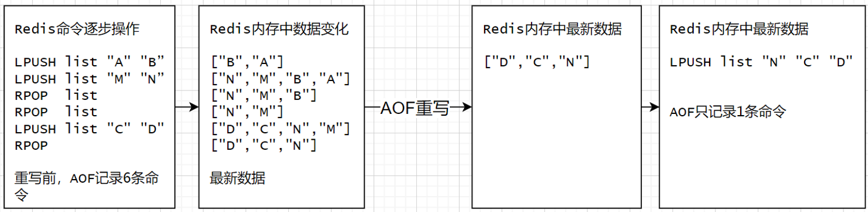
一份拷贝,两处日志
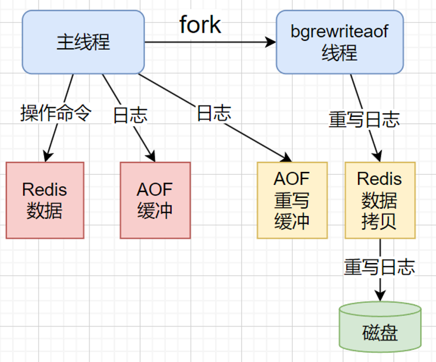
重写命令:bgrewriteaof
相关配置(不用修改) auto-aof-rewrite-min-size 64MB。 (最小重写大小) Auto-aof-rewrite-percentage 100 (文件大小翻倍的时候触发重写,为0时禁用自动重写)
2. RDB快照
- RDB配置:默认开启
- 快照频繁选择
3. 混合持久化
- 开启AOF后混合模式自动生效 aof-use-rdb-preamble yes
4. 选择
- 业务对数据安全要求极高===》混合模式
- 业务可以容忍分钟级别的数据丢失===〉只用RDB
- AOF:优先推荐每秒写回===》不建议单独使用AOF
五、高可靠篇
1. 高可靠性:
- 数据尽量少丢失:日志
- 服务尽量少中断:集群
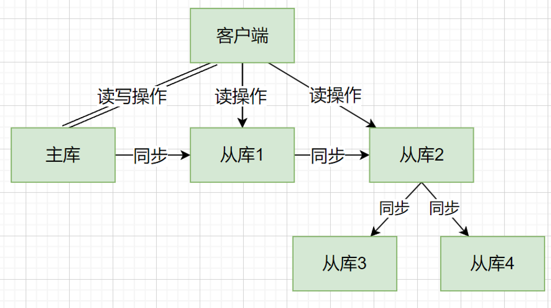
2. 主从集群模式
设置主从库同步
- 读操作:主从都可以处理
- 写操作:必须先在主库执行==》再由主库同步写操作给从库
主从同步的三个阶段
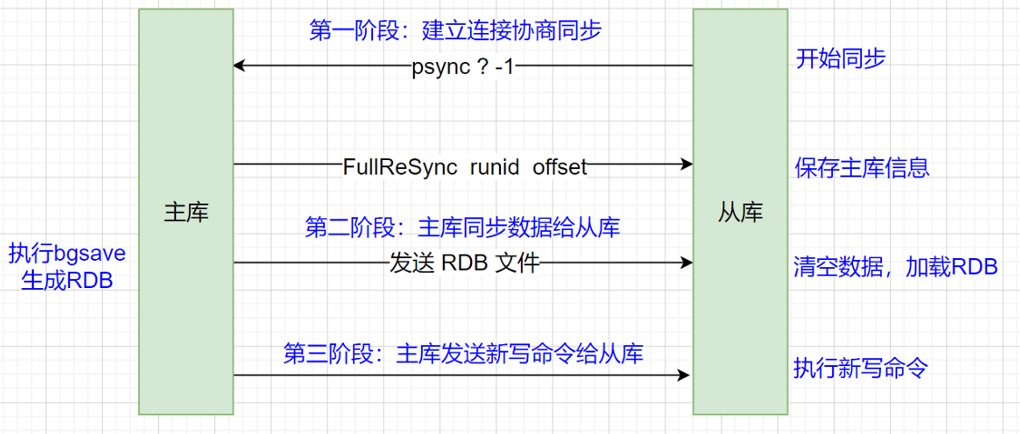
主从级联模式
- repl_backlog_size:环形缓冲区,可以适当调大
主从集群故障问题
- 主库仍然是单点
- 从库===》切换到主库:
- 如何确认主库真的挂了
- 众多从库中,选哪个成为主库
- 如何将新主库的信息下发给其他从库以及客户端
3. 哨兵模式
哨兵机制基本流程
- 独立的redis线程(哨兵模式):监控、选主、通知
主观下线和客观下线
主官下线===》从库===〉ping===》超时===〉主观下线 客观下线===》主库===〉主观下线===》询问其他哨兵===〉如果其他大多数主观下线===》客观下线
选主策略
筛选:
- 从库正常在线
- 考察历史
打分
- 从库优先级
- 从库复制进度
- 从库ID号: runId
一主二从三哨兵
六、缓存篇
1. 基础概念
- 缓存命中:有
- 缓存缺失:没有
- 缓存更新
2. 旁路缓存
- 读取数据==》调用get操作==〉更新缓存
- 缓存缺失==》链接数据库==〉读数据
- 更新到缓存==》调用set操作==〉写入缓存
读写缓存: 同步直写策略(保证缓存和数据库的更新操作具有原子性) 异步写回策略
只读缓存:
- 新增数据==》直接写到数据库==〉符合一致性
- 删改数据==》更新数据库+缓存中删除旧数据
先删缓存-再删数据库
先更新数据库-再删缓存 重试机制==〉更新或删除的操作==》暂存到消息队列
并发场景: 先删缓存、再更新数据库:延迟双删
先更新数据、再删除缓存
建议先删除数据
3. 缓存淘汰策略
- noeviction 不淘汰数据
- 过期数据淘汰
- volatile-random
- volatile-tel
- volatile-lru
- volatile-flu
- 所有数据淘汰
- allkeys-randow
- allkeys-lru
- allkeys-lfu
- 随机策略
- TTL过期策略:过期时间的先后顺序来进行删除
- LRU算法策略:最近最少使用,数据新鲜度,动态、社交
- LFU算法策略:最不经常使用==〉增加计数器===》统计访问量,数据的热度,热榜、头条、热搜
- 优先考虑allkeys-lru
4. 缓存异常
缓存不一致
- 缓存中有这条数据时,那么缓存中的数据值,必须和数据库中的值完全相同
- 缓存中没有这条数据时,数据库中的值必须时当前最新的值
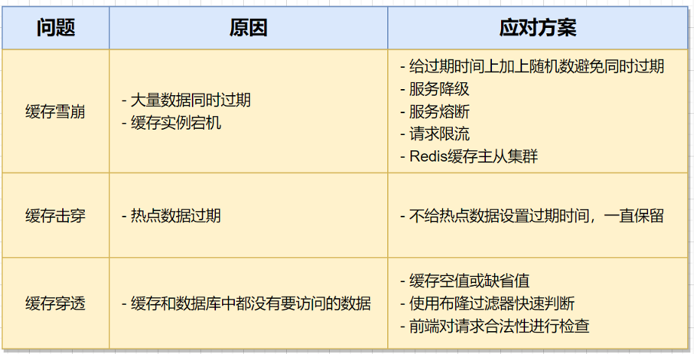
缓存雪崩:
在某一时间内,大量的应用请求都无法在redis缓存中得到处理,请求绕过来缓存,巨大的压力传到了数据库
原因:
- 大量的缓存数据,集中过期:避免设置相同的过期设置
- 服务降级:暂时牺牲一些非核心服务
缓存击穿
- 针对某一个访问巨大、非常频繁的热点数据的请求,突然无法在缓存中进行处理
- 原因:某个热点数据刚好过期失效:不设置过期时间
缓存穿透
- 用户想要的数据,既不在redis中,也不在数据库中
- 原因:
- 业务层的误操作
- 恶意的攻击行为
- 应对:
- 击穿空值/缺省值
- 使用补隆过滤器来快速判断数据是否存在(初始全部为0的bit数组,n个不同的哈希函数组成的)
- 请求的入口、进行有效的检测(api网关近希合法性校验)