Net企业级AI项目3:构建企业知识库
2025-09-20 20:49:45一、理论基础
1. RAG 概述
RAG:检索增强生成技术,我们先用一个例子来介绍一下什么是检索增强生成。
想象一下,你是一个很聪明的小学生,但你的知识都记在脑子里。如果老师问你一个很难的问题,比如:“恐龙是怎么消失的?”。你可能记得一些,但不完整。
这时候老师说:“来,我们开卷考!你可以去书架上查百科全书,然后再回答。”
RAG 就是这样:
- 你有大脑(AI 的记忆)→ 你本来就知道很多事。
- 但遇到不知道的问题→ 你先跑去“书库”(数据库、网络等)快速查找相关的资料。
- 把查到的资料和你原来的知识合在一起,用你自己的话给出一个更好的答案。
所以,RAG 就是:先查资料,再结合自己的知识回答问题。这样就不会瞎编,答案更准确、更新鲜!是不是很像写作业时“先翻书,再总结”呢?
企业应用使用大模型时,至少会遇到下面2个问题:
- 大模型一旦训练结束,它就不会在知道结束时间之后发生的事了,也就是它有时效性缺失
- 另外,通用的大模型是使用公共数据来训练的,它没有企业私有的数据,也就是私有领域空白
为了解决上面2类问题,我们可以使用 RAG 技术,为模型提供一个图书馆,也就是通常说的企业知识库。
2. RAG 工作流程
在让 LLM 回答问题之前,先去外部知识库中检索相关的信息,然后将检索到的信息作为参考资料喂给LLM,让它基于资料生成答案。RAG 分为2个阶段:
- 索引阶段:后台异步运行的数据处理流程,将文本转换为向量,构建语义索引。
- 检索与生成阶段:能够在线实时响应用户请求的流程
ETL(提取、转换、加载)流:
- 加载:格式解析、编码标准化、元数据提取;
- 分割:LLM的上下文窗口有限,所以需要递归字符分割,分割可能造成语义不完整,所以在分割的2段语句通常会添加重叠窗口;
- 嵌入:人类语言翻译成机器语言,使用嵌入模型,将文本转换为高维向量,即高维的语义空间,后续可以使用余弦相似度 -1 ~ 1进行检索;
- 存储:将文本块内容、向量数据、元数据,持久化存储到向量数据库。
3. 嵌入模型选型
我们把文本转换成高维向量时,需要使用嵌入模型,那如何选择嵌入模型呢?
我们先看一下都有哪些选择:
闭源厂商云端模型 API:
优势:接入成本低、弹性扩展
劣势:数据隐私风险、长期成本不可控、网络延迟
开源模型本地私有化:
优势:绝对的数据安全、零增量成本、高性能与低延迟
劣势:硬件门槛高、维护复杂度
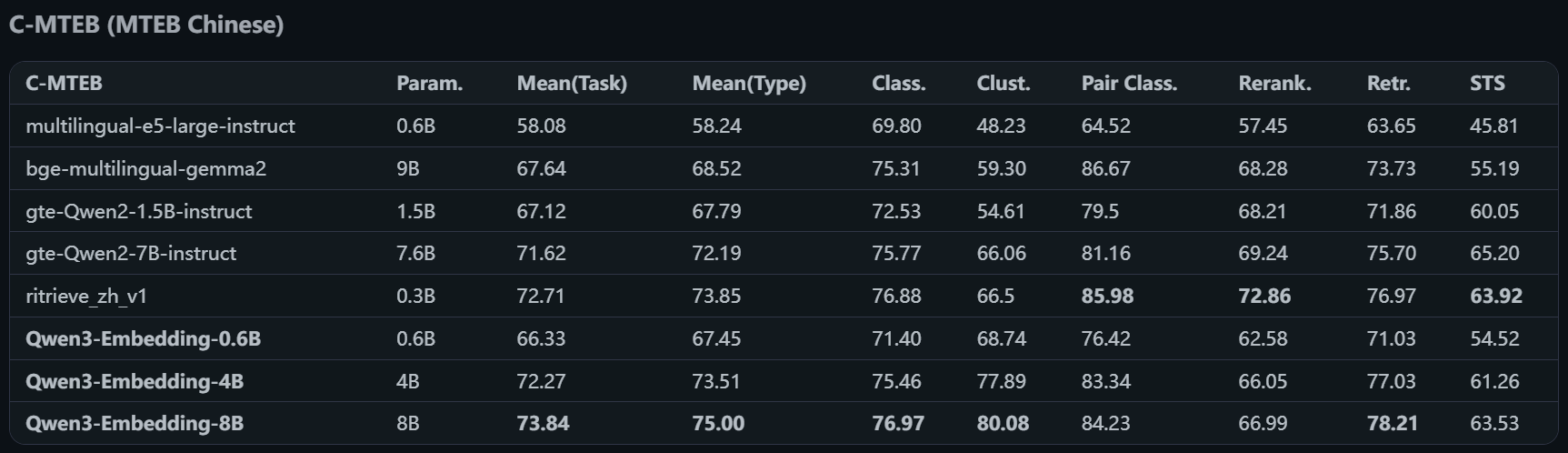
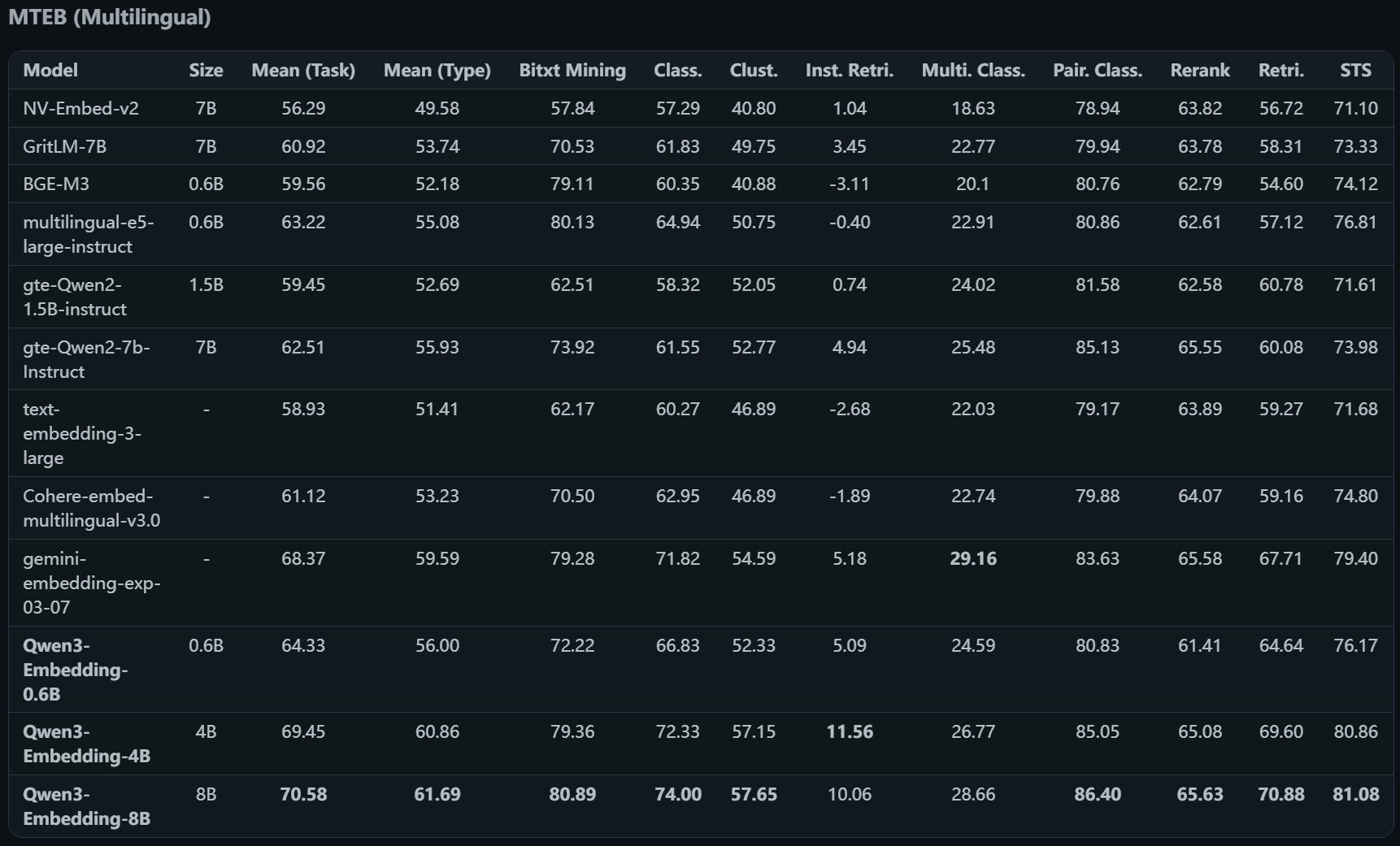
我们来看一下评测机构(MTEB)的评估数据:
- 中文模型评估
- 多语言模型评估
- 英文模型评估
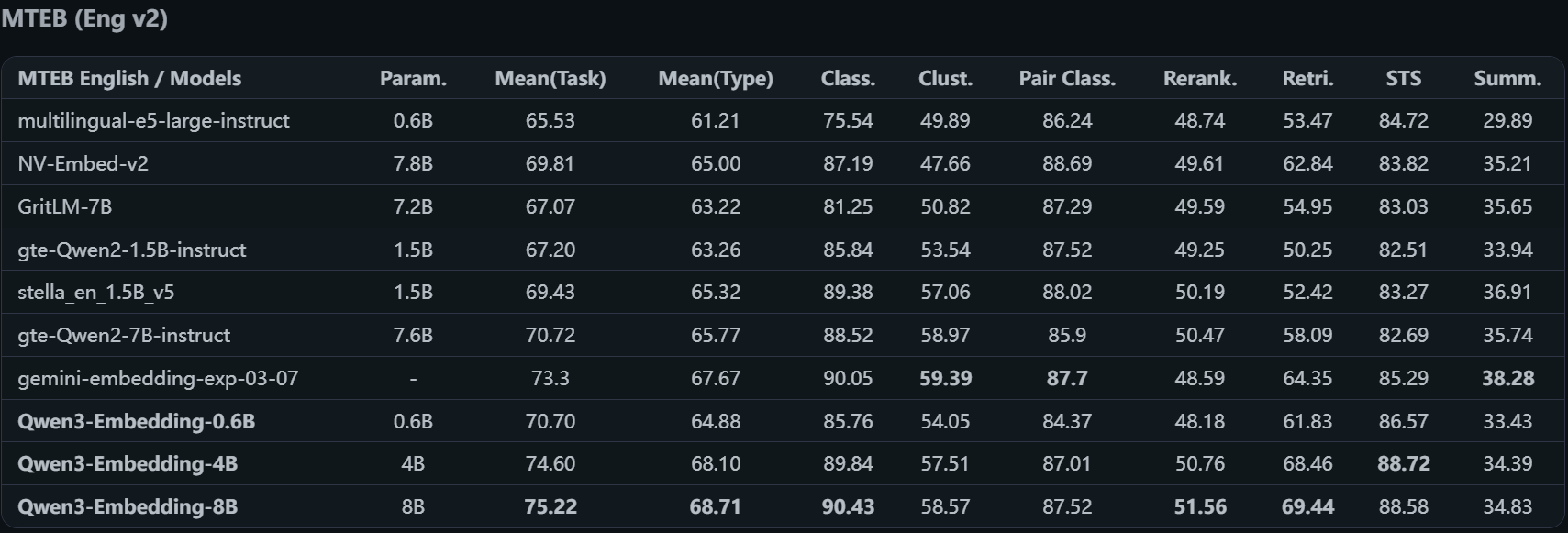
我们可以看到 Qwen3 的4B和8B模型的综合评分都是挺不错了,我们项目中使用 Qwen 的嵌入模型。
我们用5070,16G显存版本举例。
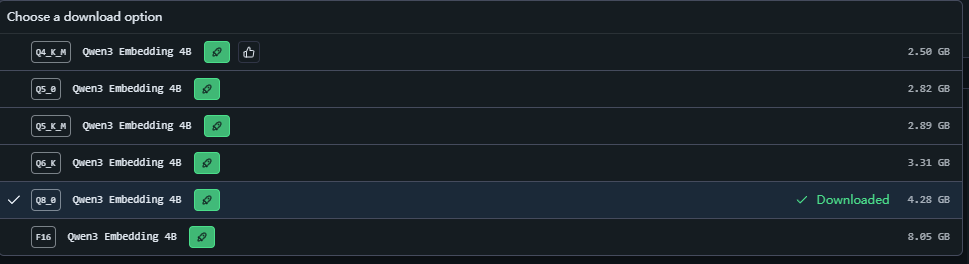
- 选择 Qwen3-Embedding-4B模型,从评测数据来看4B和8B的差距非常小,4B已经可以满足普通企业知识库的要求了。
- 下图我们选择 Q8_0 的版本,根据实践结论,Q8_0的迁入模型与FP16的几乎没有区别,但是体积小了一半,所以可以选择Q8_0:
- FP16:表示存储的数据是16位浮点数
- INT8(Q8_0):是把数据映射为8位整数,体积减半
- INT4(Q4):继续将数据映射为4为整数,体积又减了一半
- 其他就是8/4位之间。
我们这里的项目实现使用 Qwen 的云端 API,因为我电脑配置不够,就不演示怎么本地化部署了。
私有部署可以使用 LM Studio 或者 Ollma 来实现。
二、构建 RAG 应用服务
1. 领域层设计
- 嵌入模型聚合
- 嵌入模型实体:EmbeddingModel
- 知识库聚合:
- 知识库实体:KnowledgeBase
- 文档实体:Document
- 文档块实体:DocumentChunk
代码实现:我们在 Core 目录创建一个新的类库项目 Qjy.AICopilot.Core.Rag
//Qjy.AICopilot.Core.Rag/Aggregates/EmbeddingModel/EmbeddingModel.cs
public class EmbeddingModel : IAggregateRoot
{
protected EmbeddingModel()
{
}
public EmbeddingModel(
Guid id,
string provider,
string name,
string baseUrl,
string apiKey,
string modelName,
int dimensions,
int maxTokens)
{
Id = id;
Name = name;
Provider = provider;
BaseUrl = baseUrl;
ApiKey = apiKey;
ModelName = modelName;
Dimensions = dimensions;
MaxTokens = maxTokens;
IsEnabled = true;
}
public Guid Id { get; private set; }
/// <summary>
/// 显示名称 (如: "OpenAI V3 Small")
/// </summary>
public string Name { get; private set; } = string.Empty;
/// <summary>
/// 模型提供商标识 (如: "OpenAI", "AzureOpenAI", "Ollama")
/// </summary>
public string Provider { get; private set; } = string.Empty;
/// <summary>
/// 模型提供者的 API BaseUrl
/// </summary>
public string BaseUrl { get; private set; } = string.Empty;
/// <summary>
/// 模型提供商的 API Key(没有保持为空)
/// </summary>
public string? ApiKey { get; private set; }
/// <summary>
/// 实际的模型标识符 (如: "text-embedding-3-small")
/// </summary>
public string ModelName { get; private set; } = string.Empty;
/// <summary>
/// 向量维度 (如: 1536, 768, 1024)
/// </summary>
public int Dimensions { get; private set; }
/// <summary>
/// 最大上下文 Token 限制 (如: 8191)
/// 用于在分割阶段校验切片大小是否超标
/// </summary>
public int MaxTokens { get; private set; }
/// <summary>
/// 是否启用
/// </summary>
public bool IsEnabled { get; private set; } = true;
}
//Qjy.AICopilot.Core.Rag/Aggregates/KnowledgeBase/KnowledgeBase.cs
public class KnowledgeBase : IAggregateRoot
{
private readonly List<Document> _documents = [];
protected KnowledgeBase()
{
}
public KnowledgeBase(string name, string description, Guid embeddingModelId)
{
Id = Guid.NewGuid();
Name = name;
Description = description;
EmbeddingModelId = embeddingModelId;
}
public Guid Id { get; private set; }
public string Name { get; private set; } = string.Empty;
public string Description { get; private set; } = string.Empty;
/// <summary>
/// 嵌入模型ID。一个知识库内的所有文档必须使用相同的嵌入模型。
/// </summary>
public Guid EmbeddingModelId { get; private set; }
// 导航属性:对外只暴露只读集合
public IReadOnlyCollection<Document> Documents => _documents.AsReadOnly();
/// <summary>
/// 添加新文档到知识库
/// </summary>
public Document AddDocument(string name, string filePath, string extension, string fileHash)
{
var document = new Document(Id, name, filePath, extension, fileHash);
_documents.Add(document);
return document;
}
/// <summary>
/// 移除文档
/// </summary>
public void RemoveDocument(int documentId)
{
var doc = _documents.FirstOrDefault(d => d.Id == documentId);
if (doc != null)
{
_documents.Remove(doc);
}
}
public void UpdateInfo(string name, string description)
{
Name = name;
Description = description;
}
}
//Qjy.AICopilot.Core.Rag/Aggregates/KnowledgeBase/Document.cs
public class Document : IEntity<int>
{
private readonly List<DocumentChunk> _chunks = [];
protected Document()
{
}
internal Document(Guid knowledgeBaseId, string name, string filePath, string extension, string fileHash)
{
KnowledgeBaseId = knowledgeBaseId;
Name = name;
FilePath = filePath;
Extension = extension;
FileHash = fileHash;
Status = DocumentStatus.Pending;
CreatedAt = DateTime.UtcNow;
}
public int Id { get; private set; }
public Guid KnowledgeBaseId { get; private set; }
/// <summary>
/// 原始文件名
/// </summary>
public string Name { get; private set; } = string.Empty;
/// <summary>
/// 文件存储路径
/// </summary>
public string FilePath { get; private set; } = string.Empty;
/// <summary>
/// 文件扩展名
/// </summary>
public string Extension { get; private set; } = string.Empty;
/// <summary>
/// 文件哈希值
/// </summary>
public string FileHash { get; private set; } = string.Empty;
/// <summary>
/// 文档处理状态
/// </summary>
public DocumentStatus Status { get; private set; }
/// <summary>
/// 切片数量
/// </summary>
public int ChunkCount { get; private set; }
/// <summary>
/// 错误信息
/// </summary>
public string? ErrorMessage { get; private set; }
public DateTime CreatedAt { get; private set; }
public DateTime? ProcessedAt { get; private set; }
// 导航属性
public KnowledgeBase KnowledgeBase { get; private set; } = null!;
public IReadOnlyCollection<DocumentChunk> Chunks => _chunks.AsReadOnly();
#region 领域行为方法
/// <summary>
/// 开始解析文档
/// </summary>
public void StartParsing()
{
if (Status != DocumentStatus.Pending && Status != DocumentStatus.Failed)
throw new InvalidOperationException($"当前状态 {Status} 不允许开始解析");
Status = DocumentStatus.Parsing;
ErrorMessage = null;
}
/// <summary>
/// 完成解析,准备切片
/// </summary>
public void CompleteParsing()
{
if (Status != DocumentStatus.Parsing) return;
Status = DocumentStatus.Splitting;
}
/// <summary>
/// 添加文档切片
/// </summary>
public void AddChunk(int index, string content)
{
// 允许在 Splitting 或 Embedding 阶段添加/重新生成切片
if (Status != DocumentStatus.Splitting && Status != DocumentStatus.Embedding)
throw new InvalidOperationException($"当前状态 {Status} 不允许添加切片");
var chunk = new DocumentChunk(Id, index, content);
_chunks.Add(chunk);
ChunkCount = _chunks.Count;
}
/// <summary>
/// 清空所有切片(例如重新处理时)
/// </summary>
public void ClearChunks()
{
_chunks.Clear();
ChunkCount = 0;
}
/// <summary>
/// 开始向量化
/// </summary>
public void StartEmbedding()
{
Status = DocumentStatus.Embedding;
}
/// <summary>
/// 标记切片已向量化完成(更新向量ID)
/// </summary>
public void MarkChunkAsEmbedded(int chunkId, string vectorId)
{
var chunk = _chunks.FirstOrDefault(c => c.Id == chunkId);
chunk?.SetVectorId(vectorId);
}
/// <summary>
/// 文档处理全部完成
/// </summary>
public void MarkAsIndexed()
{
Status = DocumentStatus.Indexed;
ProcessedAt = DateTime.UtcNow;
}
/// <summary>
/// 标记处理失败
/// </summary>
public void MarkAsFailed(string errorMessage)
{
Status = DocumentStatus.Failed;
ErrorMessage = errorMessage;
}
#endregion
}
public enum DocumentStatus
{
Pending = 0, // 等待处理
Parsing = 1, // 正在读取/解析内容
Splitting = 2, // 正在进行文本切片
Embedding = 3, // 正在调用模型生成向量
Indexed = 4, // 索引完成,可用于检索
Failed = 5 // 处理失败
}
//Qjy.AICopilot.Core.Rag/Aggregates/KnowledgeBase/DocumentChunk.cs
public class DocumentChunk : IEntity<int>
{
protected DocumentChunk()
{
}
internal DocumentChunk(int documentId, int index, string content)
{
DocumentId = documentId;
Index = index;
Content = content;
CreatedAt = DateTime.UtcNow;
}
public int Id { get; private set; }
public int DocumentId { get; private set; }
/// <summary>
/// 切片序号
/// </summary>
public int Index { get; private set; }
/// <summary>
/// 文本内容
/// </summary>
public string Content { get; private set; } = string.Empty;
/// <summary>
/// 向量数据库中的ID
/// </summary>
public string? VectorId { get; private set; }
public DateTime CreatedAt { get; private set; }
// 导航属性
public Document Document { get; private set; } = null!;
/// <summary>
/// 设置向量ID (当向量化完成后调用)
/// </summary>
public void SetVectorId(string vectorId)
{
VectorId = vectorId;
}
}
2. 数据库映射
//Qjy.AICopilot.EntityFrameworkCore/Configuration/Rag/EmbeddingModelConfiguration.cs
public class EmbeddingModelConfiguration : IEntityTypeConfiguration<EmbeddingModel>
{
public void Configure(EntityTypeBuilder<EmbeddingModel> builder)
{
builder.ToTable("embedding_models");
builder.HasKey(e => e.Id);
builder.Property(e => e.Id).HasColumnName("id");
builder.Property(e => e.Name)
.IsRequired()
.HasMaxLength(100)
.HasColumnName("name");
// 建议添加唯一索引,防止同名模型
builder.HasIndex(e => e.Name).IsUnique();
builder.Property(e => e.Provider)
.IsRequired()
.HasMaxLength(50)
.HasColumnName("provider");
builder.Property(e => e.BaseUrl)
.IsRequired()
.HasMaxLength(500)
.HasColumnName("base_url");
builder.Property(e => e.ApiKey)
.HasMaxLength(256)
.HasColumnName("api_key");
builder.Property(e => e.ModelName)
.IsRequired()
.HasMaxLength(100)
.HasColumnName("model_name");
builder.Property(e => e.Dimensions)
.IsRequired()
.HasColumnName("dimensions");
builder.Property(e => e.MaxTokens)
.IsRequired()
.HasColumnName("max_tokens");
builder.Property(e => e.IsEnabled)
.IsRequired()
.HasColumnName("is_enabled");
}
}
//Qjy.AICopilot.EntityFrameworkCore/Configuration/Rag/KnowledgeBaseConfiguration.cs
public class KnowledgeBaseConfiguration : IEntityTypeConfiguration<KnowledgeBase>
{
public void Configure(EntityTypeBuilder<KnowledgeBase> builder)
{
builder.ToTable("knowledge_bases");
builder.HasKey(kb => kb.Id);
builder.Property(kb => kb.Id).HasColumnName("id");
builder.Property(kb => kb.Name)
.IsRequired()
.HasMaxLength(200)
.HasColumnName("name");
builder.Property(kb => kb.Description)
.HasMaxLength(1000)
.HasColumnName("description");
builder.Property(kb => kb.EmbeddingModelId)
.IsRequired()
.HasColumnName("embedding_model_id");
// 配置导航属性 Documents
builder.HasMany(kb => kb.Documents)
.WithOne(d => d.KnowledgeBase)
.HasForeignKey(d => d.KnowledgeBaseId)
.IsRequired()
.OnDelete(DeleteBehavior.Cascade); // 删除知识库时级联删除文档
}
}
//Qjy.AICopilot.EntityFrameworkCore/Configuration/Rag/DocumentConfiguration
public class DocumentConfiguration : IEntityTypeConfiguration<Document>
{
public void Configure(EntityTypeBuilder<Document> builder)
{
builder.ToTable("documents");
builder.HasKey(d => d.Id);
builder.Property(d => d.Id).HasColumnName("id")
.ValueGeneratedOnAdd();
builder.Property(d => d.KnowledgeBaseId)
.IsRequired()
.HasColumnName("knowledge_base_id");
builder.Property(d => d.Name)
.IsRequired()
.HasMaxLength(256)
.HasColumnName("name");
builder.Property(d => d.FilePath)
.IsRequired()
.HasMaxLength(500)
.HasColumnName("file_path");
builder.Property(d => d.Extension)
.IsRequired()
.HasMaxLength(50)
.HasColumnName("extension");
builder.Property(d => d.FileHash)
.IsRequired()
.HasMaxLength(64) // 使用 SHA256,通常为 64 字符
.HasColumnName("file_hash");
// 状态枚举:建议存为字符串,方便数据库直观查看
builder.Property(d => d.Status)
.IsRequired()
.HasMaxLength(50)
.HasConversion<string>()
.HasColumnName("status");
builder.Property(d => d.ChunkCount)
.IsRequired()
.HasColumnName("chunk_count");
builder.Property(d => d.ErrorMessage)
.HasColumnName("error_message"); // 允许为空
builder.Property(d => d.CreatedAt)
.IsRequired()
.HasColumnName("created_at");
builder.Property(d => d.ProcessedAt)
.HasColumnName("processed_at"); // 允许为空
// 配置导航属性 Chunks
builder.HasMany(d => d.Chunks)
.WithOne(c => c.Document)
.HasForeignKey(c => c.DocumentId)
.IsRequired()
.OnDelete(DeleteBehavior.Cascade); // 删除文档时级联删除切片
}
}
//Qjy.AICopilot.EntityFrameworkCore/Configuration/Rag/DocumentChunkConfiguration
public class DocumentChunkConfiguration : IEntityTypeConfiguration<DocumentChunk>
{
public void Configure(EntityTypeBuilder<DocumentChunk> builder)
{
builder.ToTable("document_chunks");
builder.HasKey(c => c.Id);
builder.Property(c => c.Id).HasColumnName("id")
.ValueGeneratedOnAdd();
builder.Property(c => c.DocumentId)
.IsRequired()
.HasColumnName("document_id");
builder.Property(c => c.Index)
.IsRequired()
.HasColumnName("index");
// 内容字段,根据数据库类型可能需要配置为 TEXT
builder.Property(c => c.Content)
.IsRequired()
.HasColumnType("text")
.HasColumnName("content");
builder.Property(c => c.VectorId)
.HasMaxLength(100)
.HasColumnName("vector_id"); // 允许为空,因为刚切分完可能还没向量化
builder.Property(c => c.CreatedAt)
.IsRequired()
.HasColumnName("created_at");
// 索引配置:通常会根据文档ID查询切片,并按顺序排序
builder.HasIndex(c => new { c.DocumentId, c.Index })
.IsUnique(); // 保证同一文档内切片序号不重复
}
}
- 提供 DbSet
public class AiCopilotDbContext(DbContextOptions<AiCopilotDbContext> options) : IdentityDbContext(options)
{
// RAG 实体模型
public DbSet<EmbeddingModel> EmbeddingModels => Set<EmbeddingModel>();
public DbSet<KnowledgeBase> KnowledgeBases => Set<KnowledgeBase>();
public DbSet<Document> Documents => Set<Document>();
public DbSet<DocumentChunk> DocumentChunks => Set<DocumentChunk>();
}
- 扩展数据查询服务
//Qjy.AICopilot.Services.Common/Contracts/IDataQueryService.cs
public IQueryable<EmbeddingModel> EmbeddingModels { get; }
public IQueryable<KnowledgeBase> KnowledgeBases { get; }
public IQueryable<Document> Documents { get; }
public IQueryable<DocumentChunk> DocumentChunks { get; }
//Qjy.AICopilot.EntityFrameworkCore/DataQueryService.cs
public IQueryable<EmbeddingModel> EmbeddingModels => dbContext.EmbeddingModels.AsNoTracking();
public IQueryable<KnowledgeBase> KnowledgeBases => dbContext.KnowledgeBases.AsNoTracking();
public IQueryable<Document> Documents => dbContext.Documents.AsNoTracking();
public IQueryable<DocumentChunk> DocumentChunks => dbContext.DocumentChunks.AsNoTracking();
- 种子数据
//Qjy.AICopilot.MigrationWorkApp/SeedData/RagData.cs
public static class RagData
{
private static readonly Guid[] Guids =
[
Guid.NewGuid()
];
public static IEnumerable<EmbeddingModel> EmbeddingModels()
{
// 如果是本地部署,嵌入模型的种子数据示例
//var item1 = new EmbeddingModel(
// Guids[0],
// "Qwen3-4B-Q8_0",
// "Qwen",
// "http://127.0.0.1:1234/v1", // LM Studio API 端点
// "text-embedding-qwen3-embedding-4b", // LM Studio 中的名称
// 2560,
// 32 * 1000);
var item1 = new EmbeddingModel(
Guids[0],
"Qwen",
"Qwen3-4B-Q8_0",
"https://dashscope.aliyuncs.com/compatible-mode/v1",
"sk-xxx",
"text-embedding-v4",
2560,
32 * 1000);
return [item1];
}
public static IEnumerable<KnowledgeBase> KnowledgeBases()
{
var item1 = new KnowledgeBase("默认知识库", "系统默认知识库", Guids[0]);
return [item1];
}
}
//Qjy.AICopilot.MigrationWorkApp/Worker.cs
private static async Task SeedDataAsync(
AiCopilotDbContext dbContext,
RoleManager<IdentityRole> roleManager,
UserManager<IdentityUser> userManager,
CancellationToken cancellationToken)
{
// ...其他代码
// 创建默认知识库
if (!await dbContext.KnowledgeBases.AnyAsync(cancellationToken: cancellationToken))
{
await dbContext.KnowledgeBases.AddRangeAsync(RagData.KnowledgeBases(), cancellationToken);
}
await dbContext.SaveChangesAsync(cancellationToken);
}
- 数据库迁移
可以直接删除 docker 中的数据卷,删除 Migrations,重新生成,生成命令在 Qjy.AICopilot.EntityFrameworkCore/readme.md 里面。
//Qjy.AICopilot.EntityFrameworkCore/readme.md
"C:\Program Files\dotnet\dotnet.exe" ef migrations add --project Qjy.AICopilot.EntityFrameworkCore\Qjy.AICopilot.EntityFrameworkCore.csproj --startup-project Qjy.AICopilot.HttpApi\Qjy.AICopilot.HttpApi.csproj --context Qjy.AICopilot.EntityFrameworkCore.AiCopilotDbContext --configuration Debug Initial --output-dir Migrations
3. 文件存储服务
文件存储是一个易变需求,它可能是一个本地存储、OSS存储,或者 minio 存储,所以我们要为 RAG 文件存储服务提供一个抽象接口,默认实现本地文件存储。
//Qjy.AICopilot.Services.Common/Contracts/IFileStorageService.cs
public interface IFileStorageService
{
/// <summary>
/// 保存文件
/// </summary>
/// <param name="stream">文件流</param>
/// <param name="fileName">文件名</param>
/// <param name="cancellationToken"></param>
Task<string> SaveAsync(Stream stream, string fileName, CancellationToken cancellationToken = default);
/// <returns>返回相对存储路径或URL</returns>
/// <summary>
/// 获取文件流
/// </summary>
/// <param name="path">文件路径</param>
/// <returns></returns>
Task<Stream?> GetAsync(string path, CancellationToken cancellationToken = default);
/// <summary>
/// 删除文件
/// </summary>
/// <param name="path"></param>
/// <returns></returns>
Task DeleteAsync(string path, CancellationToken cancellationToken = default);
}
//Qjy.AICopilot.Infrastructure/Storage/LocalFileStorageService.cs
public class LocalFileStorageService : IFileStorageService
{
private const string RootPath = "C:\\";
private const string UploadRoot = "uploads";
public async Task<string> SaveAsync(Stream stream, string fileName, CancellationToken cancellationToken = default)
{
// 1. 构建存储路径:uploads/2025/12/01/guid_filename.pdf
var datePath = DateTime.Now.ToString("yyyy/MM/dd");
var uniqueFileName = $"{Guid.NewGuid()}_{fileName}";
var relativePath = Path.Combine(UploadRoot, datePath);
var fullDirectory = Path.Combine(RootPath, relativePath);
if (!Directory.Exists(fullDirectory))
{
Directory.CreateDirectory(fullDirectory);
}
var fullPath = Path.Combine(fullDirectory, uniqueFileName);
// 2. 写入文件
await using var fileStream = new FileStream(fullPath, FileMode.Create);
if (stream.CanSeek) stream.Position = 0;
await stream.CopyToAsync(fileStream, cancellationToken);
// 3. 返回相对路径(统一使用正斜杠,方便跨平台和URL访问)
return Path.Combine(relativePath, uniqueFileName).Replace("\\", "/");
}
public Task<Stream?> GetAsync(string path, CancellationToken cancellationToken = default)
{
var fullPath = Path.Combine(RootPath, path);
if (!File.Exists(fullPath)) return Task.FromResult<Stream?>(null);
var stream = new FileStream(fullPath, FileMode.Open, FileAccess.Read);
return Task.FromResult<Stream?>(stream);
}
public Task DeleteAsync(string path, CancellationToken cancellationToken = default)
{
var fullPath = Path.Combine(RootPath, path);
if (File.Exists(fullPath))
{
File.Delete(fullPath);
}
return Task.CompletedTask;
}
}
4. 消息总线
我们使用 RabbitMQ 来做消息队列,使用 MassTransit 实现消息总线。
- 在 Asprise 中添加 RabbitMQ ,添加 Aspire.Hosting.RabbitMQ 的引用
//Qjy.AICopilot.AppHost/AppHost.cs
var rabbitmq = builder.AddRabbitMQ("eventbus")
.WithManagementPlugin()
.WithLifetime(ContainerLifetime.Persistent);
// 启动主Api项目
builder.AddProject<Qjy_AICopilot_HttpApi>("aicopilot-httpapi")
.WithUrl("swagger")
.WaitFor(postgresdb)
.WaitFor(rabbitmq)
.WithReference(postgresdb)
.WithReference(rabbitmq)
.WithReference(migration)
.WaitForCompletion(migration);
- 创建消息总线基础设施:我们只需要引用 MassTransit.RabbitMQ,再添加配置即可。我们创建在 Infrastructure 目录一个新的类库项目 Qjy.AICopilot.EventBus
//Qjy.AICopilot.EventBus/DependencyInjection.cs
public static class DependencyInjection
{
public static void AddEventBus(this IHostApplicationBuilder builder, params Assembly[] assemblies)
{
builder.Services.AddMassTransit(x =>
{
if (assemblies.Length > 0)
{
x.AddConsumers(assemblies);
}
x.SetKebabCaseEndpointNameFormatter();
// 默认配置 RabbitMQ
x.UsingRabbitMq((context, cfg) =>
{
// 从 Aspire 注入的连接字符串中读取配置
// 连接字符串名必须与 AppHost 中 .AddRabbitMQ("eventbus") 的名称一致
var connectionString = builder.Configuration.GetConnectionString("eventbus");
cfg.Host(connectionString);
cfg.ConfigureEndpoints(context);
});
});
}
}
5. 实现 RAG 应用服务
领域建模和基础设施完成后,我们可以来实现 RAG 应用服务了。
RAG数据接入过程:
- 用户通过 API 创建知识库
- 用户上传文件(异步)
- 系统计算文件Hash(幂等性)
- 现在数据库生成文档记录
- 发送消息到RabbitMQ
在 Services 目录创建新的类库项目 Qjy.AICopilot.RagService
- 创建知识库命令
//Qjy.AICopilot.RagService/Commands/KnowledgeBases/CreateKnowledgeBase.cs
public record CreatedKnowledgeBaseDto(Guid Id, string Name);
[AuthorizeRequirement("Rag.CreateKnowledgeBase")]
public record CreateKnowledgeBaseCommand(
string Name,
string Description,
Guid EmbeddingModelId) : ICommand<Result<CreatedKnowledgeBaseDto>>;
public class CreateKnowledgeBaseCommandHandler(
IRepository<KnowledgeBase> kbRepo,
IReadRepository<EmbeddingModel> modelRepo)
: ICommandHandler<CreateKnowledgeBaseCommand, Result<CreatedKnowledgeBaseDto>>
{
public async Task<Result<CreatedKnowledgeBaseDto>> Handle(
CreateKnowledgeBaseCommand request,
CancellationToken cancellationToken)
{
// 1. 校验嵌入模型是否存在
// 知识库必须绑定一个具体的 Embedding 模型,因为这决定了向量的维度
var embeddingModel = await modelRepo.GetByIdAsync(request.EmbeddingModelId, cancellationToken);
if (embeddingModel == null)
{
return Result.NotFound("指定的嵌入模型不存在");
}
// 2. 创建实体
var kb = new KnowledgeBase(request.Name, request.Description, request.EmbeddingModelId);
// 3. 持久化
kbRepo.Add(kb);
await kbRepo.SaveChangesAsync(cancellationToken);
return Result.Success(new CreatedKnowledgeBaseDto(kb.Id, kb.Name));
}
}
- 定义文档上传事件对象
//Qjy.AICopilot.Services.Common/Events/DocumentUploadedEvent.cs
public record DocumentUploadedEvent
{
public Guid KnowledgeBaseId { get; init; }
public int DocumentId { get; init; }
public string FilePath { get; init; } = string.Empty;
public string FileName { get; init; } = string.Empty;
}
- 上传文档命令
//Qjy.AICopilot.RagService/Commands/Documents/UploadDocument.cs
public record UploadDocumentDto(int Id, string Status);
public record FileUploadStream(string FileName, Stream Stream);
[AuthorizeRequirement("Rag.UploadDocument")]
public record UploadDocumentCommand(
Guid KnowledgeBaseId,
FileUploadStream File) : ICommand<Result<UploadDocumentDto>>;
public class UploadDocumentCommandHandler(
IRepository<KnowledgeBase> kbRepo,
IFileStorageService fileStorage,
IPublishEndpoint publishEndpoint)
: ICommandHandler<UploadDocumentCommand, Result<UploadDocumentDto>>
{
public async Task<Result<UploadDocumentDto>> Handle(
UploadDocumentCommand request,
CancellationToken cancellationToken)
{
// 1. 获取知识库聚合根(并急切加载 Documents 集合)
// 使用我们刚扩展的 GetAsync 方法,通过 includes 参数加载子实体
var kb = await kbRepo.GetAsync(
kb => kb.Id == request.KnowledgeBaseId,
includes: [k => k.Documents],
cancellationToken);
if (kb == null) return Result.NotFound("知识库不存在");
// 2. 计算文件 Hash (SHA256)
string fileHash;
using (var sha256 = SHA256.Create())
{
// 确保流从头开始
if (request.File.Stream.CanSeek) request.File.Stream.Position = 0;
var hashBytes = await sha256.ComputeHashAsync(request.File.Stream, cancellationToken);
fileHash = BitConverter.ToString(hashBytes).Replace("-", "").ToLowerInvariant();
// 计算完 Hash 后,必须重置流位置,否则后续保存文件时会读到空内容
if (request.File.Stream.CanSeek) request.File.Stream.Position = 0;
}
// 3. 检查文件是否已存在 (基于 Hash 实现幂等性)
// 因为 Documents 已经加载到内存中,我们可以直接使用 LINQ 查询
var existingDoc = kb.Documents.FirstOrDefault(d => d.FileHash == fileHash);
if (existingDoc != null)
{
// 如果文件已存在,直接返回成功,并返回现有的文档 ID
// 这实现了接口的幂等性:多次上传同一文件不会产生副作用
return Result.Success(new UploadDocumentDto(existingDoc.Id, existingDoc.Status.ToString()));
}
// 4. 保存物理文件 (只有当文件不存在时才执行 IO 操作)
var extension = Path.GetExtension(request.File.FileName).ToLower();
var savedPath = await fileStorage.SaveAsync(request.File.Stream, request.File.FileName, cancellationToken);
// 5. 领域模型行为:添加文档
// 这一步是纯内存操作,修改了聚合根的状态
var document = kb.AddDocument(request.File.FileName, savedPath, extension, fileHash);
// 6. 持久化到数据库
await kbRepo.SaveChangesAsync(cancellationToken);
// 7. 发送集成事件 (通知后台 Worker 开始索引)
await publishEndpoint.Publish(new DocumentUploadedEvent
{
DocumentId = document.Id,
KnowledgeBaseId = kb.Id,
FilePath = savedPath,
FileName = request.File.FileName
}, cancellationToken);
return Result.Success(new UploadDocumentDto(document.Id, document.Status.ToString()));
}
}
- 配置依赖注入
//Qjy.AICopilot.RagService/DependencyInjection.cs
public static class DependencyInjection
{
public static void AddRagService(this IHostApplicationBuilder builder)
{
builder.Services.AddMediatR(cfg =>
{
cfg.RegisterServicesFromAssembly(Assembly.GetExecutingAssembly());
});
builder.AddEventBus();
}
}
//Qjy.AICopilot.HttpApi/DependencyInjection.cs
public void AddApplicationService()
{
builder.AddRagService();
}
**6. 实现 API **
//Qjy.AICopilot.HttpApi/Controllers/RagController.cs
[Route("/api/rag")]
[Authorize]
public class RagController : ApiControllerBase
{
/// <summary>
/// 创建知识库
/// </summary>
[HttpPost("knowledge-base")]
public async Task<IActionResult> CreateKnowledgeBase(CreateKnowledgeBaseCommand command)
{
var result = await Sender.Send(command);
return ReturnResult(result);
}
/// <summary>
/// 上传文档
/// </summary>
[HttpPost("document")]
[DisableRequestSizeLimit] // 允许上传大文件
public async Task<IActionResult> UploadDocument(
[FromForm] Guid knowledgeBaseId,
IFormFile file)
{
if (file.Length == 0)
{
return BadRequest(new { error = "请选择文件" });
}
// 将 IFormFile 转换为流
await using var stream = file.OpenReadStream();
var command = new UploadDocumentCommand(
knowledgeBaseId,
new FileUploadStream(file.FileName, stream));
var result = await Sender.Send(command);
return ReturnResult(result);
}
}
7. 测试上传文档
- 先从 pgsql 找到种子数据生成的 knowledgeBaseId,如 0f18f4c3-12ef-4204-80a7-e77acd8fe3ef
- 上传项目中 data 目录下的《计算机原理.md》文件
- 查看 C 盘下的文件是否成功上传
- 查看数据库中表 documents 的数据字段 status 的值,应该是 Parsing
三、实现 RAG 后台服务
1. 创建后台服务
- 首先,我们在 Hosts 目录创建辅助角色项目 Qjy.AICopilot.RagWorker,配置 Worker
//Qjy.AICopilot.RagWorker/Worker.cs
public class Worker(ILogger<Worker> logger) : BackgroundService
{
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
if (logger.IsEnabled(LogLevel.Information))
{
logger.LogInformation("Worker running at: {time}", DateTimeOffset.Now);
}
await Task.Delay(1000, stoppingToken);
}
}
}
- 在 Program 完成启动配置和依赖注入
//Qjy.AICopilot.RagWorker/Program.cs
var builder = Host.CreateApplicationBuilder(args);
// 1. 添加 Aspire 服务默认配置
builder.AddServiceDefaults();
// 2. 注册数据库上下文 (PostgreSQL)
// 这里的连接字符串名称需与 AppHost 中定义的一致
builder.AddNpgsqlDbContext<AiCopilotDbContext>("ai-copilot");
// 3. 注册文件存储服务
// 必须与 HttpApi 使用相同的存储实现,确保能读取到上传的文件
builder.Services.AddSingleton<IFileStorageService, LocalFileStorageService>();
// 4. 注册事件总线 (RabbitMQ)
// 将自动扫描当前程序集下的 Consumer
builder.AddEventBus(typeof(Program).Assembly);
// 注册解析器
builder.Services.AddSingleton<IDocumentParser, PdfDocumentParser>();
builder.Services.AddSingleton<IDocumentParser, TextDocumentParser>();
// 注册工厂
builder.Services.AddSingleton<DocumentParserFactory>();
builder.Services.AddScoped<RagService>();
// 注册Token计数器
builder.Services.AddSingleton<ITokenCounter, SharpTokenCounter>();
// 文本分割
builder.Services.AddSingleton<TextSplitterService>();
// 注册嵌入生成器工厂
builder.Services.AddSingleton<EmbeddingGeneratorFactory>();
// 注册嵌入服务专用的 HttpClient
builder.Services.AddHttpClient("EmbeddingClient", client =>
{
client.Timeout = TimeSpan.FromMinutes(20);
});
// 注册 Qdrant 客户端
// QdrantClient 是官方客户端,Semantic Kernel 会对其进行封装
builder.AddQdrantClient("qdrant");
// 注册 Semantic Kernel 的 Qdrant 向量存储抽象
builder.Services.AddQdrantVectorStore();
var host = builder.Build();
host.Run();
上面注册类中有一些会在后续实现,先把整个注册代码放这里了
- 定义 RAG 索引嵌入服务骨架
//Qjy.AICopilot.RagWorker/Services/RagService.cs
public class RagService(
IFileStorageService fileStorage,
AiCopilotDbContext dbContext,
ILogger<RagService> logger)
{
public async Task IndexDocumentAsync(Document document, CancellationToken cancellationToken = new())
{
logger.LogInformation("开始索引流程: {DocumentName}", document.Name);
// Step 1: 加载
var stream = await LoadDocumentAsync(document, cancellationToken);
// Step 2: 解析
// var text = await ParseDocumentAsync(document, stream, cancellationToken);
// Step 3: 分割
// var paragraphs = await SplitDocumentAsync(document, text, cancellationToken);
// Step 4: 嵌入
// var (embeddings, dimensions) = await GenerateEmbeddingsAsync(document, paragraphs, cancellationToken);
// Step 5: 存储
// await SaveVectorAsync(document, paragraphs, embeddings, dimensions, cancellationToken);
logger.LogInformation("文档索引完成: {DocumentName}", document.Name);
}
// ================================================================
// Step 1: 加载
// ================================================================
private async Task<Stream> LoadDocumentAsync(Document document, CancellationToken ct)
{
logger.LogInformation("加载文档...");
// 从存储中获取文件流
var stream = await fileStorage.GetAsync(document.FilePath, ct);
return stream ?? throw new FileNotFoundException($"文件未找到: {document.FilePath}");
}
}
Step 1 - 5 的方法目前都没有实现,这里只是一个定义,后续我们一步一步实现这些具体方法,实现对应方法后在取消对应的注释,后面的部分不再展示 IndexDocumentAsync 的代码了。
- 实现文档上传事件的消费者
//Qjy.AICopilot.RagWorker/Consumers/DocumentUploadedConsumer.cs
public class DocumentUploadedConsumer(
RagService ragService,
AiCopilotDbContext dbContext,
ILogger<DocumentUploadedConsumer> logger)
: IConsumer<DocumentUploadedEvent>
{
public async Task Consume(ConsumeContext<DocumentUploadedEvent> context)
{
var message = context.Message;
logger.LogInformation("接收到文档处理请求: {DocumentId}, 文件: {FileName}", message.DocumentId, message.FileName);
// 1. 获取文档实体 (包含 KnowledgeBase 信息)
var document = await dbContext.Documents
.Include(d => d.KnowledgeBase)
.FirstOrDefaultAsync(d => d.Id == message.DocumentId);
if (document == null)
{
logger.LogWarning("文档 {DocumentId} 未在数据库中找到,跳过处理。", message.DocumentId);
return;
}
// 2. 幂等性与状态检查
// 如果文档已经处理成功(Indexed)或正在处理中(Parsing/Splitting/Embedding),则忽略
// 除非是 Failed 状态,才允许重试
if (document.Status != DocumentStatus.Pending && document.Status != DocumentStatus.Failed)
{
logger.LogInformation("文档 {DocumentId} 当前状态为 {Status},无需重复处理。", message.DocumentId, document.Status);
return;
}
try
{
// 3. 开始处理 - 状态流转
document.StartParsing();
await dbContext.SaveChangesAsync();
// TODO: 调用核心 ETL 流程 (Parse -> Split -> Embed -> Store)
await ragService.IndexDocumentAsync(document);
// 模拟处理成功
logger.LogInformation("文档 {DocumentId} 索引流程执行完毕。", message.DocumentId);
}
catch (Exception ex)
{
logger.LogError(ex, "文档 {DocumentId} 处理失败。", message.DocumentId);
// 4. 异常处理 - 记录错误状态
// 重新从数据库获取最新状态(防止并发冲突),标记为失败
var errorDoc = await dbContext.Documents.FindAsync(message.DocumentId);
if (errorDoc != null)
{
errorDoc.MarkAsFailed(ex.Message);
await dbContext.SaveChangesAsync();
}
// 根据业务需求,决定是否抛出异常以触发 RabbitMQ 的重试机制
// 这里我们选择吞掉异常,因为已经记录了 Failed 状态,避免死信队列堆积
}
}
}
- Asprise 启动后台服务
builder.AddProject<Qjy_AICopilot_RagWorker>("rag-worker")
.WithReference(postgresdb) // 注入数据库连接
.WithReference(rabbitmq) // 注入 RabbitMQ 连接
.WaitFor(postgresdb) // 等待数据库启动
.WaitFor(rabbitmq); // 等待 MQ 启动
2. 文档解析
文档有很多不同格式,比如 PDF、txt、markdown 等,不同文档格式的文件加载方式是有区别了。为了实现不同格式文件的加载,我们需要实现一个文档加载工厂,然后根据文件的格式(后缀名)来创建不同的加载器来加载内容。
- 实现 pdf 和 txt 两种格式的加载器
//Qjy.AICopilot.RagWorker/Services/Parsers/IDocumentParser.cs
public interface IDocumentParser
{
/// <summary>
/// 支持的文件扩展名 (如 ".pdf")
/// </summary>
string[] SupportedExtensions { get; }
/// <summary>
/// 解析文件流为纯文本
/// </summary>
/// <param name="stream">文件流</param>
/// <returns>提取出的文本内容</returns>
Task<string> ParseAsync(Stream stream, CancellationToken cancellationToken = default);
}
//Qjy.AICopilot.RagWorker/Services/Parsers/DocumentParserFactory.cs
public class DocumentParserFactory(IEnumerable<IDocumentParser> parsers)
{
public IDocumentParser GetParser(string extension)
{
var ext = extension.ToLowerInvariant();
// 查找支持该扩展名的解析器
var parser = parsers.FirstOrDefault(p => p.SupportedExtensions.Any(e => e == ext));
return parser ?? throw new NotSupportedException($"不支持的文件格式: {extension}");
}
}
//Qjy.AICopilot.RagWorker/Services/Parsers/TextDocumentParser.cs
public class TextDocumentParser : IDocumentParser
{
// 支持多种纯文本格式
public string[] SupportedExtensions => [".txt", ".md", ".json", ".xml"];
public async Task<string> ParseAsync(Stream stream, CancellationToken cancellationToken = default)
{
// 自动检测编码,默认 UTF-8
using var reader = new StreamReader(stream, Encoding.UTF8, detectEncodingFromByteOrderMarks: true);
return await reader.ReadToEndAsync(cancellationToken);
}
}
//Qjy.AICopilot.RagWorker/Services/Parsers/PdfDocumentParser.cs
public class PdfDocumentParser : IDocumentParser
{
public string[] SupportedExtensions => [".pdf"];
public Task<string> ParseAsync(Stream stream, CancellationToken cancellationToken = default)
{
return Task.Run(() =>
{
var sb = new StringBuilder();
try
{
// PdfPig 需要 Seekable 流,如果流不支持 Seek,需要复制到 MemoryStream
using var pdfDocument = PdfDocument.Open(stream);
foreach (var page in pdfDocument.GetPages())
{
// 提取每一页的文本,并用换行符分隔
// 实际生产中可能需要更复杂的版面分析算法来处理多栏排版
var text = page.Text;
if (!string.IsNullOrWhiteSpace(text))
{
sb.AppendLine(text);
}
}
}
catch (Exception ex)
{
throw new InvalidOperationException("PDF 解析失败,文件可能已损坏或加密。", ex);
}
return sb.ToString();
}, cancellationToken);
}
}
我们实现的知识库只支持普通文档格式的文件,图片、视频这些多模态本项目不考虑,后续再扩展支持。
这里实现的 pdf 加载器也只能是普通文本内容的,图片内容、扫描文件、加密格式的 pdf 等,不属于本项目的实现目标。
- 完善文档加载方法
public class RagService(
IFileStorageService fileStorage,
DocumentParserFactory parserFactory,
AiCopilotDbContext dbContext,
ILogger<RagService> logger)
{
// ================================================================
// Step 2: 解析
// ================================================================
private async Task<string> ParseDocumentAsync(Document document, Stream stream, CancellationToken ct)
{
logger.LogInformation("解析文档...");
// 根据扩展名获取解析器
var parser = parserFactory.GetParser(document.Extension);
// 提取文本
var text = await parser.ParseAsync(stream, ct);
if (string.IsNullOrWhiteSpace(text))
throw new InvalidOperationException("文档内容为空或无法提取文本。");
logger.LogInformation("文本提取完成,长度: {Length} 字符", text.Length);
// 更新状态:解析完成 -> 准备切片
document.CompleteParsing();
await dbContext.SaveChangesAsync(ct);
return text;
}
}
- 测试文档解析
放开 Step 2,清楚一下 documents 表的数据,再重新上传文件,因为做了文件的幂等性检查。
查看 documents 表中数据的状态,此时 status 的值等于 Splitting
3. 文本分割(切片)
为什么要对文档进行分割呢?
- 模型上下文是有限制的,如果文档的内容大于模型上下文限制时,就必须将文档分割成多个文本块。我们用的 Qwen3-4B 模型的上下文的 32K。
- 是不是可以直接按模型上下文的大小来分割文本内容了?经验上来说这样分割也不行,因为将 32k 的文本嵌入到2560维度后会失去原始内容的意义。最佳的块大小在 300~500 Token 的短文本块最合适。
- 文本通常是有段落结构、句号、换行符,这些自然语义边界的。在文本分割时首先按自然意义分割。
- 自然语义分割后的文本如果超过了推荐的 Token 大小,我们就需要继续分割。这种情况下被分割的内容可能失去原始语义,比如“我爱吃苹果”,如果在吃和苹果之间分割了,“我爱吃”和“苹果”就失去原始语义了。为了解决语义完整性,在文本分割后,通常会在分割的文本块前后添加一个重叠窗口。
接下来我们来实现文本分割
- Token 长度估算,引用 SharpToken 库
//Qjy.AICopilot.RagWorker/Services/TokenCounter/ITokenCounter.cs
public interface ITokenCounter
{
/// <summary>
/// 计算输入文本的 Token 数量
/// </summary>
int CountTokens(string text);
}
//Qjy.AICopilot.RagWorker/Services/TokenCounter/SharpTokenCounter.cs
public class SharpTokenCounter : ITokenCounter
{
// cl100k_base 是 GPT-3.5/4 使用的编码器,对于多语言支持较好
private readonly GptEncoding _encoding = GptEncoding.GetEncoding("cl100k_base");
public int CountTokens(string text)
{
if (string.IsNullOrEmpty(text)) return 0;
// 获取 Token 列表的长度
return _encoding.Encode(text).Count;
}
}
- 使用 Semantic Kernel,完成文本处理
//Qjy.AICopilot.RagWorker/Services/TextSplitterService.cs
#pragma warning disable SKEXP0050
public class TextSplitterService(ITokenCounter tokenCounter)
{
// 默认配置:适合 Qwen3-4B 等大多数 Embedding 模型
private const int DefaultMaxTokensPerParagraph = 500;
private const int DefaultMaxTokensPerLine = 120;
private const int DefaultOverlapTokens = 50;
/// <summary>
/// 将长文本分割为语义连贯的段落列表
/// </summary>
/// <param name="text">原始文本</param>
/// <returns>切片后的文本列表</returns>
public List<string> Split(string text)
{
if (string.IsNullOrWhiteSpace(text))
{
return [];
}
// 1. 预处理:移除可能导致干扰的特殊控制字符
var cleanText = Preprocess(text);
// 2. 第一层切割:将文本按行(Line)拆分
// SK 的逻辑是先按换行符等强分隔符切成小块(Lines),再将这些 Lines 组合成 Paragraphs
// 这样可以确保尽量不在句子中间强行截断
var lines = TextChunker.SplitPlainTextLines(
cleanText,
maxTokensPerLine: DefaultMaxTokensPerLine,
tokenCounter: tokenCounter.CountTokens);
// 3. 第二层组合:将 Lines 聚合成 Paragraphs
// 这一步会严格控制 Token 数量上限,并处理重叠逻辑
var paragraphs = TextChunker.SplitPlainTextParagraphs(
lines,
maxTokensPerParagraph: DefaultMaxTokensPerParagraph,
overlapTokens: DefaultOverlapTokens,
tokenCounter: tokenCounter.CountTokens);
return paragraphs;
}
private static string Preprocess(string text)
{
// 替换掉 Windows 的 \r\n 为 \n,统一换行符
// 移除 NULL 字符等
return text.Replace("\r\n", "\n").Trim();
}
}
- 流程中实现
public class RagService(
IFileStorageService fileStorage,
DocumentParserFactory parserFactory,
TextSplitterService textSplitter,
AiCopilotDbContext dbContext,
ILogger<RagService> logger)
{
// ================================================================
// Step 3: 切片
// ================================================================
private async Task<List<string>> SplitDocumentAsync(Document document, string text, CancellationToken ct)
{
logger.LogInformation("开始文本切片...");
// 为了支持重新索引,如果文档之前处理过,需要先清理旧的切片
if (document.Chunks.Count > 0)
document.ClearChunks();
var paragraphs = textSplitter.Split(text);
logger.LogInformation("文本切片完成,共 {Count} 个切片。", paragraphs.Count);
// 将切片转换为领域实体
for (var i = 0; i < paragraphs.Count; i++)
document.AddChunk(i, paragraphs[i]);
await dbContext.SaveChangesAsync(ct);
return paragraphs;
}
}
- 测试文本分割
我们用同样的方法,放开 Step 3,重新上传文档后,这次看表 document_chunks 中的数据,图中我们可以看到文本被分割成了17份。
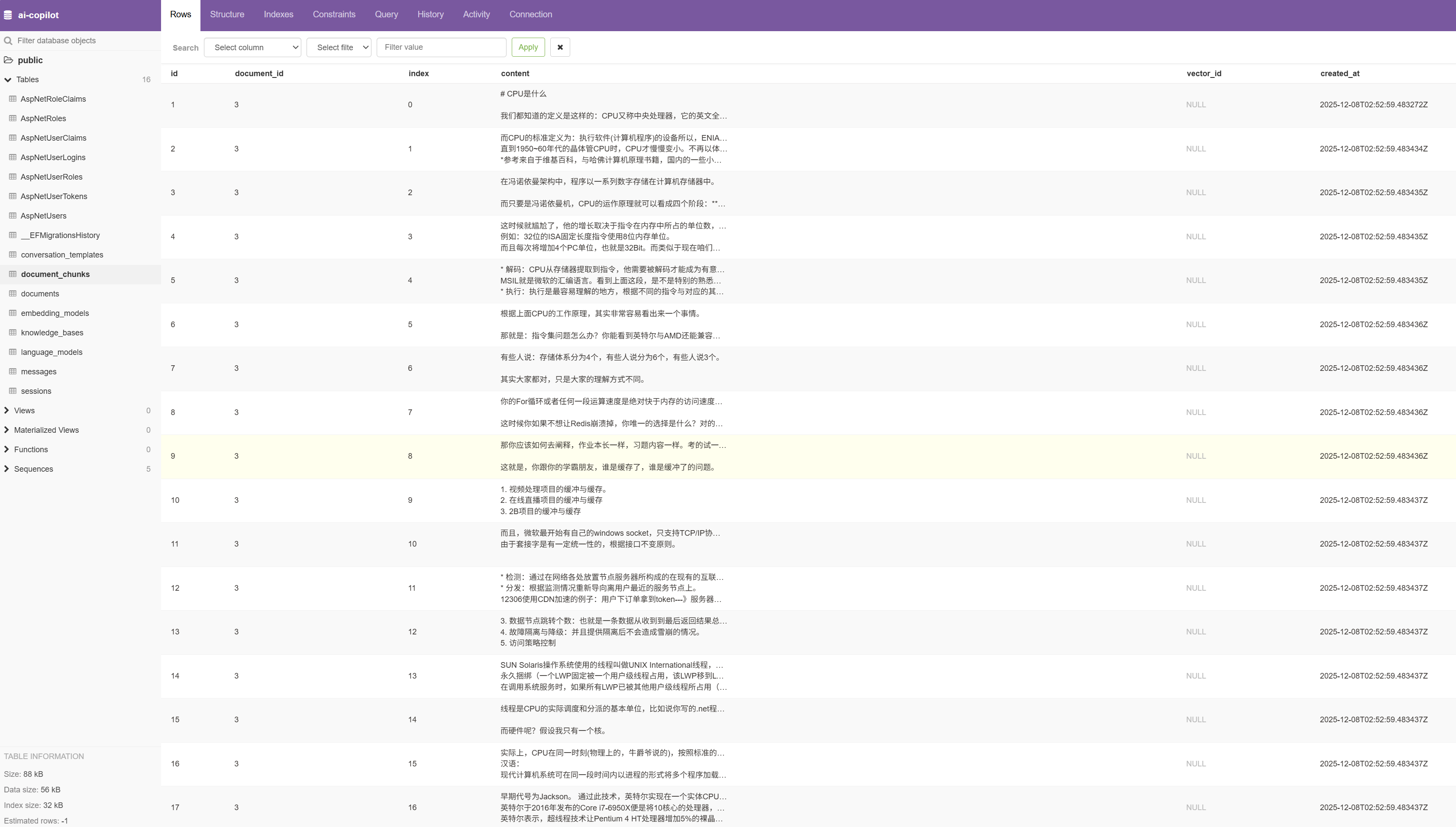
ps:document_chunks 表的数据是用来观察文档分割的过程的,开发中建议添加这张表,用于测试。生产上也可以不用保存分割后的数据到数据库,因为分割的数据会保存到向量数据库中。
4. 文本嵌入
文本嵌入就是自然语言转换为数值向量的过程,因为我们的项目设计初衷是支持多模型的,虽然我们使用的是 Qwen3 的云端迁入模型,为了支持未来切换模型,我们需要提供一个嵌入模型的工厂类
- 实现嵌入模型工厂
//Qjy.AICopilot.RagWorker/Services/Embeddings/EmbeddingGeneratorFactory.cs
public class EmbeddingGeneratorFactory(IHttpClientFactory httpClientFactory)
{
public IEmbeddingGenerator<string, Embedding<float>> CreateGenerator(EmbeddingModel model)
{
var endpoint = new Uri(model.BaseUrl);
var credential = new ApiKeyCredential(model.ApiKey ?? "sk-empty");
var httpClient = httpClientFactory.CreateClient("EmbeddingClient");
var options = new OpenAIClientOptions
{
Endpoint = endpoint,
// 使用 IHttpClientFactory 创建 HttpClient,复用连接池
Transport = new HttpClientPipelineTransport(httpClient),
NetworkTimeout = TimeSpan.FromMinutes(20)
};
// 创建 OpenAI 客户端
var client = new OpenAIClient(credential, options);
return client
.GetEmbeddingClient(model.ModelName)
.AsIEmbeddingGenerator(model.Dimensions);
}
}
- 实现文本迁入
public class RagService(
IFileStorageService fileStorage,
DocumentParserFactory parserFactory,
TextSplitterService textSplitter,
EmbeddingGeneratorFactory embeddingFactory,
AiCopilotDbContext dbContext,
ILogger<RagService> logger)
{
// ================================================================
// Step 4: 嵌入
// ================================================================
private async Task<(List<Embedding<float>>, int)> GenerateEmbeddingsAsync(
Document document,
List<string> paragraphs,
CancellationToken ct)
{
logger.LogInformation("开始生成嵌入向量...");
// 获取嵌入模型配置
var embeddingModelConfig = await dbContext.EmbeddingModels.AsNoTracking()
.FirstOrDefaultAsync(em => em.Id == document.KnowledgeBase.EmbeddingModelId,
cancellationToken: ct);
if (embeddingModelConfig == null)
{
throw new InvalidOperationException($"未找到 ID 为 {document.KnowledgeBase.EmbeddingModelId} 的嵌入模型配置");
}
// 创建嵌入生成器
using var generator = embeddingFactory.CreateGenerator(embeddingModelConfig);
// 准备分批
// [配置建议]
// - 本地模型: 建议 20 ~ 50 (取决于显卡)
// - 云端模型: 建议 50 ~ 100
const int batchSize = 50;
// 用于收集所有生成的向量结果
var allEmbeddings = new List<Embedding<float>>();
// 将段落切分为多个批次
var batches = paragraphs.Chunk(batchSize).ToArray();
logger.LogInformation("共 {Paragraphs} 个段落,将分为 {Batches} 批处理", paragraphs.Count, batches.Length);
// 循环处理每一批
for (var i = 0; i < batches.Length; i++)
{
logger.LogInformation("正在处理第 {Current}/{Total} 批...", i + 1, batches.Length);
try
{
var batch = batches[i];
// 调用模型生成当前批次的向量
var result = await generator.GenerateAsync(batch, cancellationToken: ct);
// 将结果添加到总列表中
allEmbeddings.AddRange(result);
}
catch (Exception ex)
{
logger.LogError(ex, "第 {Batch} 批次向量化失败", i + 1);
throw;
}
}
var dimensions = allEmbeddings.First().Vector.Length;
logger.LogInformation("向量化完成,共生成 {Count} 个向量,维度: {Dim}", allEmbeddings.Count, dimensions);
return (allEmbeddings, dimensions);
}
}
- 修改弹性管道默认值,文本迁入是一个比较费时的操作,默认的请求时间只有10秒就会超时,我们需要修改这个默认值
//Qjy.AICopilot.ServiceDefaults/Extensions.cs
public static class Extensions
{
public static TBuilder AddServiceDefaults<TBuilder>(this TBuilder builder) where TBuilder : IHostApplicationBuilder
{
builder.Services.ConfigureHttpClientDefaults(http =>
{
// Turn on resilience by default
//http.AddStandardResilienceHandler();
http.AddStandardResilienceHandler(options =>
{
// 将默认的 10秒 延长到 5分钟,这对大多数 AI 场景都更友好
options.AttemptTimeout.Timeout = TimeSpan.FromMinutes(5);
options.TotalRequestTimeout.Timeout = TimeSpan.FromMinutes(10);
options.CircuitBreaker.SamplingDuration = TimeSpan.FromMinutes(10);
});
// Turn on service discovery by default
http.AddServiceDiscovery();
});
return builder;
}
}
5. 向量存储
- Asprise 配置 Qdrant 应用,我们使用 Qdrant 数据库来保存向量数据
//Qjy.AICopilot.AppHost/AppHost.csAppHost.cs
var qdrant = builder.AddQdrant("qdrant")
.WithLifetime(ContainerLifetime.Persistent);
// 启动主Api项目
builder.AddProject<Qjy_AICopilot_HttpApi>("aicopilot-httpapi")
.WithUrl("swagger")
.WaitFor(postgresdb)
.WaitFor(rabbitmq)
.WaitFor(qdrant)
.WithReference(postgresdb)
.WithReference(rabbitmq)
.WithReference(migration)
.WithReference(qdrant)
.WaitForCompletion(migration);
builder.AddProject<Qjy_AICopilot_RagWorker>("rag-worker")
.WithReference(postgresdb) // 注入数据库连接
.WithReference(rabbitmq) // 注入 RabbitMQ 连接
.WithReference(qdrant)
.WaitFor(postgresdb) // 等待数据库启动
.WaitFor(rabbitmq) // 等待 MQ 启动
.WaitFor(qdrant);
- 定义向量数据结构
//Qjy.AICopilot.RagWorker/Models/VectorDocumentDefinition.cs
//方法1
public static class VectorDocumentDefinition
{
public static VectorStoreCollectionDefinition Get(int dimensions)
{
VectorStoreCollectionDefinition definition = new()
{
Properties = new List<VectorStoreProperty>
{
new VectorStoreKeyProperty("Key", typeof(ulong)),
new VectorStoreDataProperty("Text", typeof(string)) { IsFullTextIndexed = true },
new VectorStoreDataProperty("DocumentId", typeof(string)){ IsIndexed = true },
new VectorStoreDataProperty("KnowledgeBaseId", typeof(string)){ IsIndexed = true },
new VectorStoreDataProperty("ChunkIndex", typeof(int)),
new VectorStoreVectorProperty("Embedding", typeof(ReadOnlyMemory<float>),
dimensions: dimensions)
{
DistanceFunction = DistanceFunction.CosineSimilarity,
IndexKind = IndexKind.Hnsw
}
}
};
return definition;
}
}
//Qjy.AICopilot.RagWorker/Models/VectorDocumentRecord.cs
//方法2
//这个类文件没有用到,是另一种定义项目数据结构的方法,因为我们要动态设置 dimensions,这种方式不合适。
/// <summary>
/// 对应向量数据库中的一条记录
/// </summary>
public class VectorDocumentRecord
{
/// <summary>
/// 记录的唯一标识符
/// </summary>
/// <remarks>
/// 使用 ulong 类型,因为 Qdrant 内部 ID 支持 64 位无符号整数或 UUID。
/// 这里我们不使用 Guid,而是为了与语义对齐,将在存储时生成唯一 ID。
/// </remarks>
[VectorStoreKey]
public ulong Key { get; set; }
/// <summary>
/// 原始文本内容
/// </summary>
[VectorStoreData(IsFullTextIndexed = true)]
public string Text { get; set; } = string.Empty;
/// <summary>
/// 关联的文档 ID (元数据)
/// </summary>
/// <remarks>
/// IsFilterable = true 允许我们在检索时按 DocumentId 过滤,
/// 例如:只查询特定文档的内容。
/// </remarks>
[VectorStoreData(IsIndexed = true)]
public string DocumentId { get; set; } = string.Empty;
/// <summary>
/// 关联的知识库 ID (元数据)
/// </summary>
[VectorStoreData(IsIndexed = true)]
public string KnowledgeBaseId { get; set; } = string.Empty;
/// <summary>
/// 原始切片在文档中的索引顺序
/// </summary>
[VectorStoreData]
public int ChunkIndex { get; set; }
/// <summary>
/// 嵌入向量
/// </summary>
/// <remarks>
/// Dimensions 必须与我们使用的模型(Qwen3-4B)一致,否则插入会报错。
/// DistanceFunction 定义了相似度计算方式,Cosine (余弦相似度) 是文本检索的标准选择。
/// </remarks>
[VectorStoreVector(Dimensions: 2560, DistanceFunction = DistanceFunction.CosineSimilarity, IndexKind = IndexKind.Hnsw)]
public ReadOnlyMemory<float> Embedding { get; set; }
}
- 实现向量存储
public class RagService(
IFileStorageService fileStorage,
DocumentParserFactory parserFactory,
TextSplitterService textSplitter,
EmbeddingGeneratorFactory embeddingFactory,
VectorStore vectorStoreClient,
AiCopilotDbContext dbContext,
ILogger<RagService> logger)
{
// ================================================================
// Step 5: 保存向量
// ================================================================
private async Task SaveVectorAsync(
Document document,
List<string> chunks,
List<Embedding<float>> embeddings,
int dimensions,
CancellationToken ct)
{
logger.LogInformation("保存向量数据...");
// 基础参数校验
if (chunks.Count != embeddings.Count)
{
throw new ArgumentException($"切片数量 ({chunks.Count}) 与向量数量 ({embeddings.Count}) 不一致");
}
if (chunks.Count == 0)
{
logger.LogWarning("文档 {DocumentId} 没有切片需要存储", document.Id);
}
// 2. 确定集合名称
// 使用 "kb-" 前缀加上知识库 ID (Guid) 作为集合名,确保名称符合 Qdrant 规范且唯一
var collectionName = $"kb-{document.KnowledgeBaseId:N}";
logger.LogInformation("文档 {DocumentName} 将存入集合: {CollectionName}", document.Name, collectionName);
// 3. 动态获取集合实例
var definition = VectorDocumentDefinition.Get(dimensions);
var collection = vectorStoreClient.GetDynamicCollection(collectionName, definition);
// 4. 确保集合存在
// 第一次向该知识库上传文档时,会自动创建集合
await collection.EnsureCollectionExistsAsync(ct);
// 5. 组装存储记录
try
{
for (var i = 0; i < chunks.Count; i++)
{
// 生成一个唯一的记录键值
var recordKey = (ulong)document.Id.GetHashCode() << 32 | (uint)i;
await collection.UpsertAsync(new Dictionary<string, object?>
{
{ "Key", recordKey },
{ "Text", chunks[i] },
{ "DocumentId", document.Id.ToString() },
{ "KnowledgeBaseId", document.KnowledgeBaseId.ToString() },
{ "ChunkIndex", i },
{ "Embedding", embeddings[i].Vector }
}, ct);
}
logger.LogInformation("成功向集合 {Collection} 写入 {Count} 条向量记录。", collectionName, chunks.Count);
}
catch (Exception ex)
{
logger.LogError(ex, "写入向量数据库失败。Collection: {Collection}", collectionName);
throw;
}
document.MarkAsIndexed();
await dbContext.SaveChangesAsync(ct);
}
}
- 测试文本嵌入和向量存储
放开 Step 4 和 Step 5,重新上传文档调试整个过程。documents 表中的状态此时等于 Indexed
我们可以从 Asprise 的资源页面,进入 Qdrant 的管理面板查看向量化后的数据,Qdrant 的 apikey 获取方法见下图

Qdrant 截图


