B站架构设计8:弹幕系统架构设计
2021-11-27 21:04:45一、弹幕概述
1. 弹幕的几个概念
弹幕模式 mode:
从右向左(从左到右)滚动的弹幕
底部(顶部)弹幕
代码弹幕
脚本弹幕
弹幕池 pool:
普通弹幕池
字幕弹幕
特殊弹幕
推荐弹幕
被up主屏蔽的弹幕
note: 普通弹幕池弹幕长度限制300,特殊弹幕池无长度限制
弹幕上限 maxlimit:
每个视频要展示的弹幕数,根据视频时长设置,普通弹幕 + 保护弹幕,以及推荐弹幕最大展示 maxlimit 条,字幕弹幕、特殊弹幕不受限
常规值:100,300,500,1500,3000,6000,8000,黑科技值:16000,32000
2. 弹幕的几个特点
- 实时性要求不高:
- 弹幕文件不像其他业务需要实时性的加载
- 实时性弹幕可以通过弹幕广播实现
- 一次性加载:
- 和评论业务不同,弹幕需要在视频点击播放后一次性加载,comment.bilibili.com/cid.xml
- 弹幕文件比较大
- 用户相对敏感,有些用户比较关注自己发过的弹幕是否存在
3. 弹幕的现状
- 数据总量:100亿+
- 单表记录:7000万+,且按照 cid 范围分表,导致数据分布严重不均
- 单个视频弹幕数:500w+
- 单个视频展示条数:极个别 1w+,常规 3000~8000,且一次性返回
- 单条弹幕大小:长度无上限,可以通过文本上传
- 单个弹幕文件超过 10M http://comment.bilibili.com/4279031.xml
- 数据库慢查询多如狗
二、老弹幕系统架构
1. 架构图
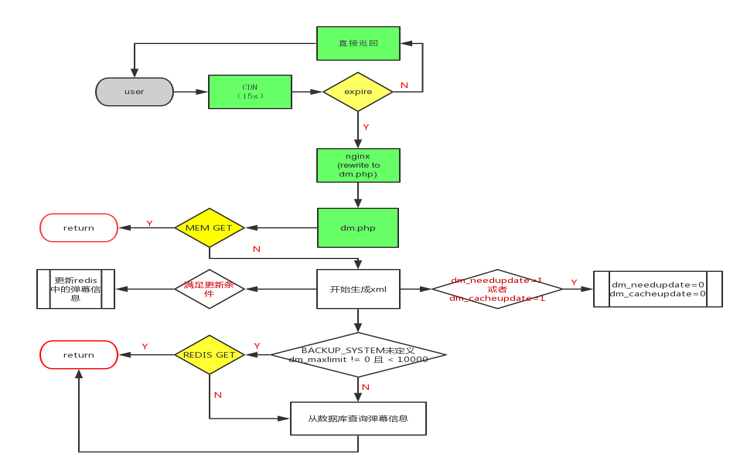
2. 老系统刷新逻辑
- dmCachecheck 通过扫描 dm_index 中的标志位来找到所有视频分批弹幕数
- 通过databus发送稿件弹幕数到 Stat-T
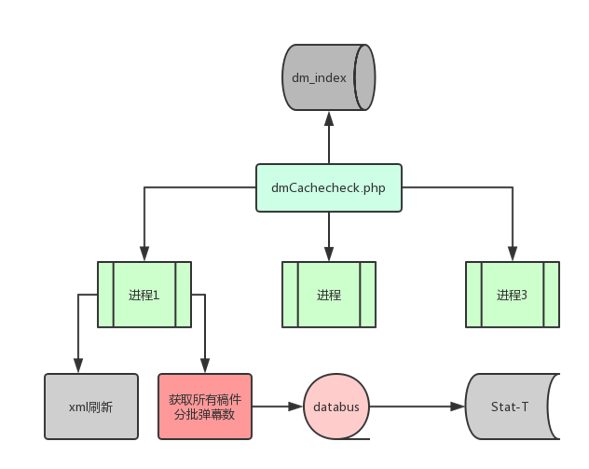
3. 老系统弹幕缓存
何时刷新缓存
- dm_needupdate: memcache缓存刷新标志
- dm_cacheupdate: memcache+redis缓存刷新标志
由于弹幕 xml 超过 1M,缓存如何存放,由于 memcache 对于大于1M文件的存取存在一些问题,因此生成缓存后将大于1M的 xml,放入NFS文件系统
优先从哪里获取缓存,老的弹幕系统在弹幕的索引 dm_index 表中增加 childpool 字段标识应该优先从哪里获取缓存,childpool=2:文件系统
标示数据来源
- header("X-Cache: HIT from fc-cluster")
- header("X-Cache: HIT from mc-cluster")
- header("X-Cache: HIT from md-cluster")
三、重构的几个手段
1. 数据库设计
重要业务单独实例,单独数据库
将弹幕数据库实例和其他服务实例分开;服务内部将重要和非重要业务分开
索引和内容分开
将经常变更的数据放入索引表,如状态、属性、弹幕池;将静态数据数据放入内容表,如弹幕内容、模式、字号、颜色;
通过分表减小单表数据量
将分表策略改为按照 cid 分表,索引表以及内容表分别分表1000张,从原来单表7000w到目前的300w
特殊弹幕内容单独存一张表
通过顶队列保证尽量少的候选集
2. 顶队列实现
鉴于单个视频弹幕候选集超过200w的情况,可以通过实现一个 redis 顶队列来保证候选集尽可能的小,redis sortset 实现如下:
- key:普通弹幕,保护弹幕,字幕弹幕,特殊弹幕,推荐弹幕
- field:fmt.Sprintf(“%d.%d”, 弹幕属性, 弹幕id)
- member:弹幕id
每次新增完之后,返回当前队列长度,将超过maxlimit的弹幕状态从正常改为隐藏状态。
每次删除一条弹幕后,则从数据库获取一条最近被隐藏的一条弹幕从隐藏改为正常
3. 智能弹幕
智能弹幕定义:大数据根据用户针对弹幕的历史行为学习,给每个用户关注的弹幕进行弹幕打分,在智能弹幕中该分值称为flag,这样每个用户看到的同一条弹幕的分值不同。
默认分值:
- 根据历史行为推荐默认 flag 等级
- 返回更多的弹幕条数保证打开智能弹幕前后尽量小的 diff
根据视频时长,分段加载弹幕
- 根据视频的时长分为6分钟一段,节省流量,减少接口压力
智能弹幕的实现:
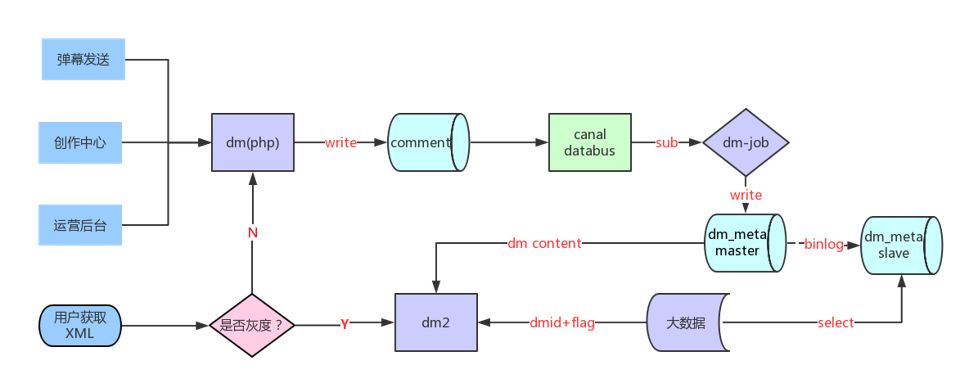
智能弹幕协议设计:弹幕 flag 信息内容长度(uint32)| 弹幕 flag 信息(json)| gzip{ xml 文本(xml)}

智能弹幕缓存:
- 一级缓存mc
- 存每个视频分段的弹幕
- 缓存每个视频的时长
- 二级缓存redis,结构sortset
- key:
- 普通弹幕: i_type_oid_cnt_n
- 特殊弹幕: s_type_oid
- 顶弹幕队列:q_oid
- score: 弹幕 id
- member: 弹幕 id
- key:
- 二级缓存redis,结构hashset
- key: c_oid
- field: 弹幕 id
- value: 单条 xml
4. 几个优化点
去除非必要逻辑,提升性能
不再解析大数据返回的弹幕id,而是直接拼装协议返回
稿件弹幕数优化,通过稿件服务拿到某个 aid 下的所有 cid,累加弹幕数后发给 Stat-T
弹幕实时性
- 新增弹幕后直接追加 memcache
- 弹幕广播接入 dm-job + goim-chat
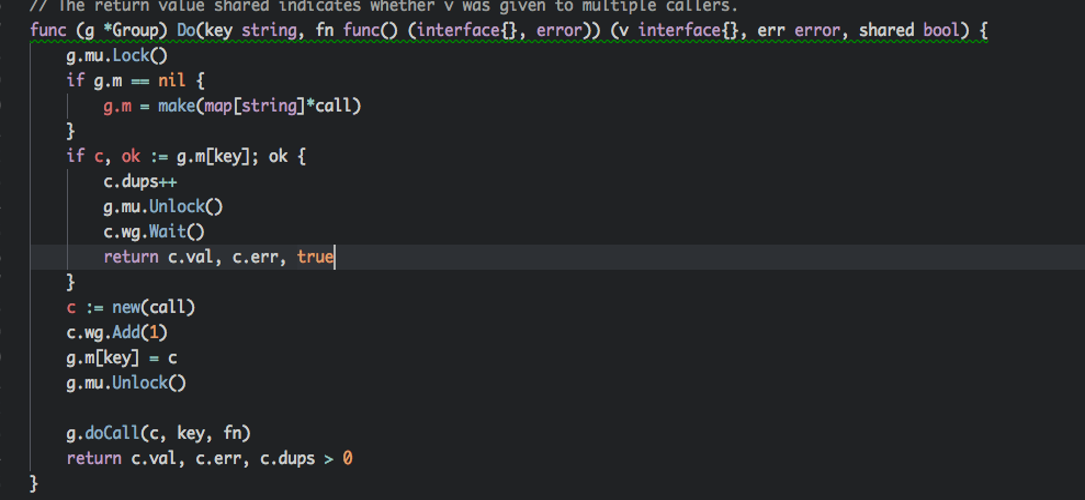
memcache 并发锁,该做法目前属于比较 low 的做法,建议会改为 single flight方式;
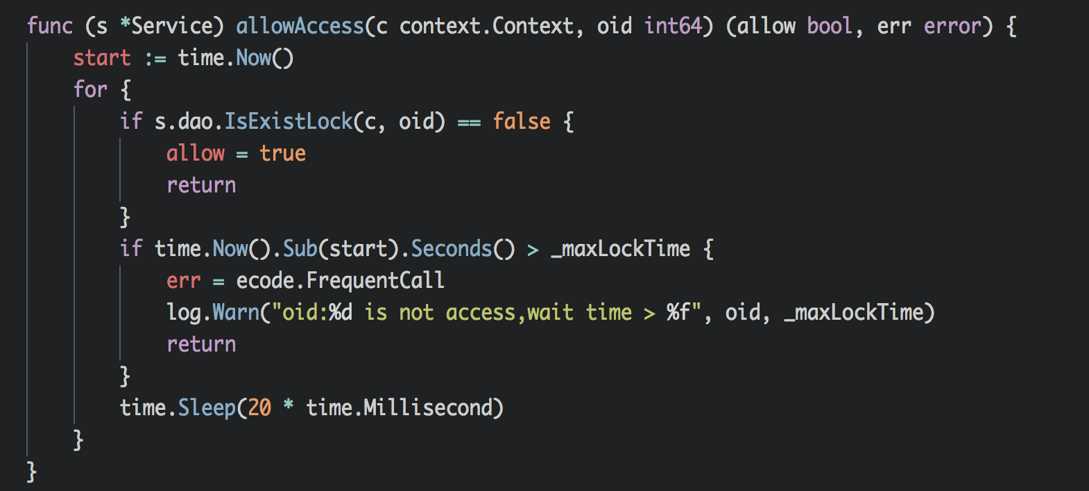
- singleflaght 并发锁
- http code 304 实现